 图
图
# 图的定义
# 1. 基本概念
图(Graph )是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
对于图的定义,我们需要明确几个注意的地方:
- 线性表中我们把数据元素叫元素,树中将数据元素叫结点。在图中的数据元素,我们则称之为顶点(Vertex);
- 线性表中可以没有数据元素,称为空表。树中可以没有结点,叫做空树。在图结构中,不允许没有顶点。在定义中,若V是顶点的集合,则强调了顶点集合V有穷非空;
- 线性表中,相邻的数据元素之间具有线性关系,树结构中,相邻两层的结点具有层次关系。而图中,任意两个顶点之间都可能有关系,顶点之间的逻辑关系用边来表示,边集可以是空的;
# 2. 各种图的定义
无向边:若顶点 vi 到 vj 之间的边没有方向,则称这条边为无向边(Edge)。
无向图:图中任意两个顶点之间的边都是无向边,则称该图为无向图(Undirected graphs)。
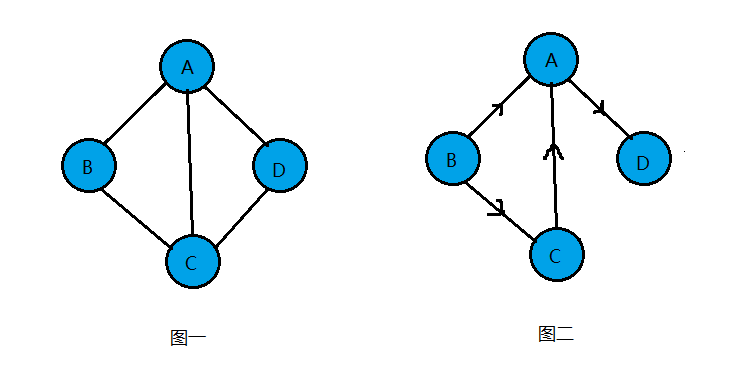
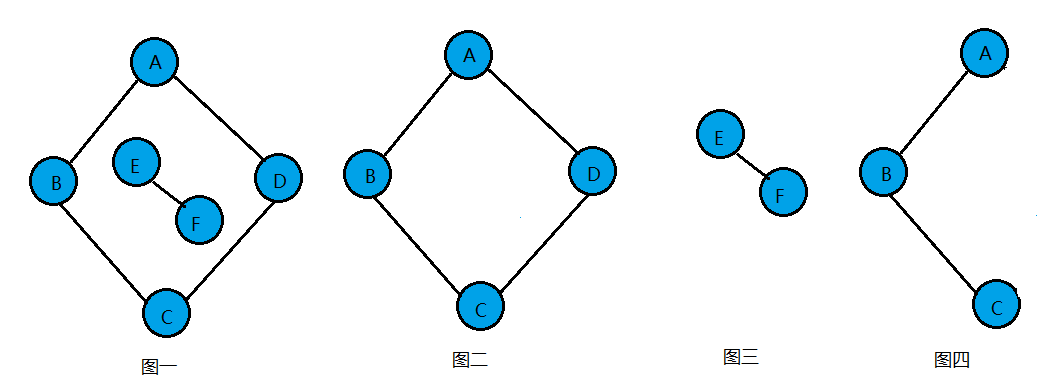
如图一就是一个无向图,由于是无方向的,连接顶点A与D的边,可以表示成无序对(A,D),也可以写成(D,A)。
有向边:若从顶点 vi 到 vj 之间的边有方向,则称这条边为有向边(Edge),也称为弧(Arc)。 用有序偶<vi, vj> 来表示,vi称为弧尾,vj称为弧头。
有向图:图中任意两个顶点之间的边都是有向边,则称该图为有向图(Directed graphs)。
如图二就是一个有向图,连接顶点A到D的有向边就是弧,A是弧尾,D是弧头,<A,D>表示弧,注意不能写成<D,A>。
注意:无向边用小括号()表示,而有向边则是用尖括号<>表示。
简单图:在图中,若不存在顶点到其自身的边,且同一条边不重复出现,则称这样的图为简单图。我们课程里要讨论的都是简单图。
无向完全图:在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图。
有向完全图:在有向图中,如果任意两个顶点之间都存在方向互为相反的两条弧,则称该图为有向完全图。
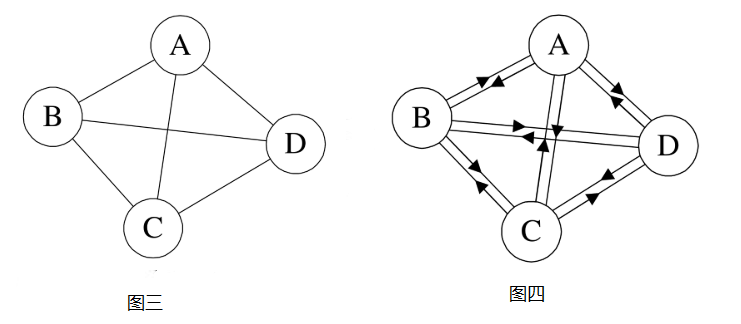
含有n个顶点的无向完全图有n*(n-1)/2条边。如图三就是无向完全图。
含有n个顶点的有向完全图有n*(n-1)条边。如图三就是有向完全图。
有很少条边或弧的图称为稀疏图,反之称为稠密图。
权:有些图的边或弧具有与它相关的数字,这种与图的边或弧相关的数叫做权(Weight)。这些权可以表示从一个顶点到另一个顶点的距离或耗费。
网:带权的图通常称为网(Network)。
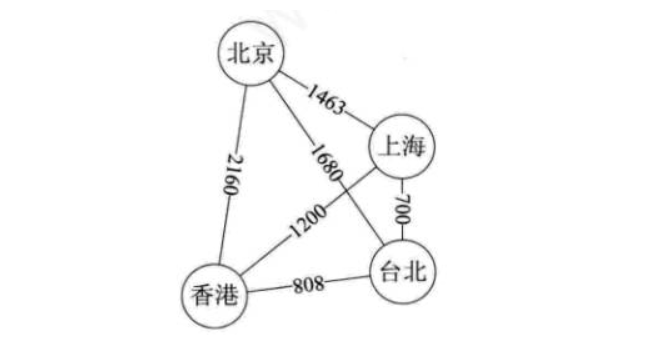
上图就是一张带权的图,即标识中国四大城市的直线距离的网,此图中的权就是两地的距离。
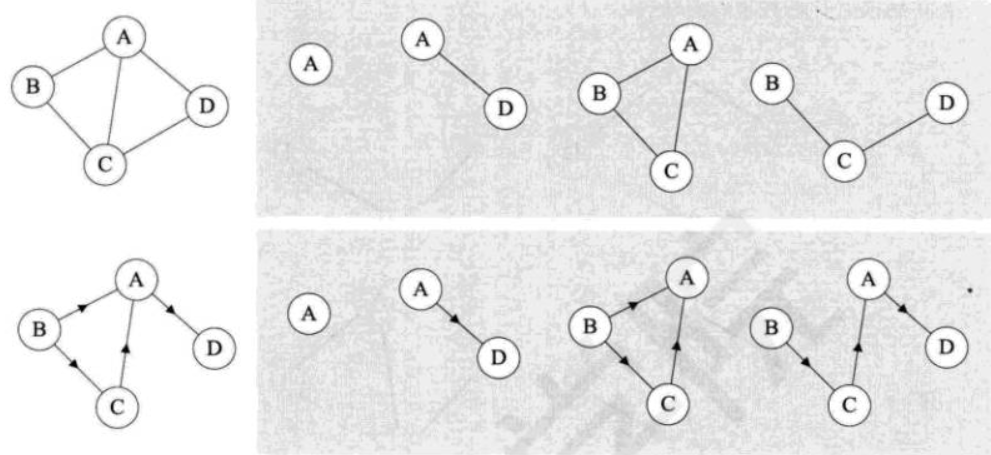
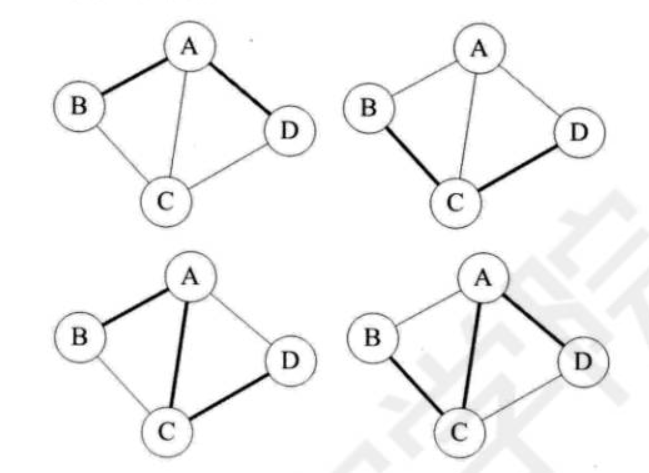
- 子图:假设有两个图 G=(V,{E}) 和 G'=(V',{E'}),如果V'∈V 且G'∈G,则称G'为G的子图。
如下图,带底纹的图均为左侧无向图与有向图的子图。
# 3. 图的顶点与边间关系
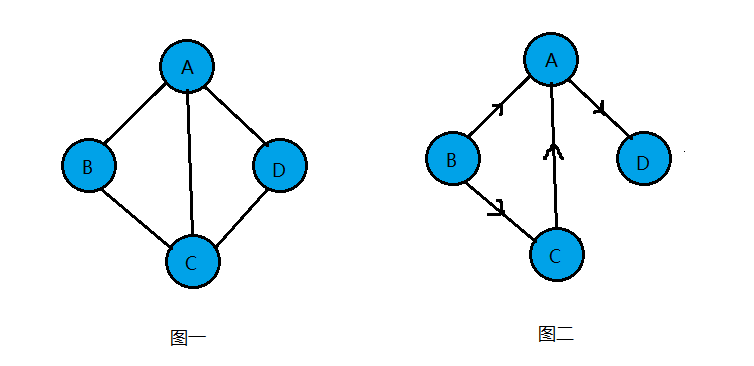
邻接点:若无向图中的两个顶点v和v'存在一条边(v,v'),则称顶点v和v'互为邻接点。 图一中顶点A和D就互为邻接点。
度:顶点v的度是和v相关联的边的数目,记作TD(v)。图一中顶点A的度为3。
而对于有向图G=(V,{E}),如果弧<v,v'>∈E,则称顶点v邻接到顶点v',顶点v'邻接自顶点v。
入度:以顶点v为头的弧的数目称为v的入度(InDegree)。记为ID(v)。
出度:以v为尾的弧的数目称为v的出度(OutDegree)。记为OD(v)。
对于有向图,顶点v的度为TD (v) =ID (v) +OD(v)。
图二有向图中顶点A的入度为2(<B,A>,<C,A>),出度为1(<A,D>),多以顶点A的度为3。
- 路径:在无向图G(V,{E})中,若从顶点v出发有一组边可到达顶点v',则称顶点v到顶点v'的顶点序列为从顶点v到顶点v'的路径(Path)
下图就列举了顶点B到顶点D四种不同的路径:
如果G是有向图,则路径也是有向的。如下图:顶点B到D有两种路径。而顶点A到B,就不存在路径。
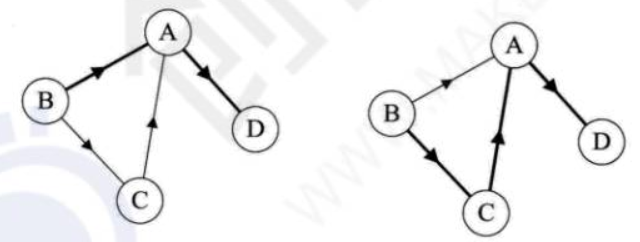
路径的长度是路径上的边或弧的数目。上图中左侧路径长为2,右侧路径长度为3。
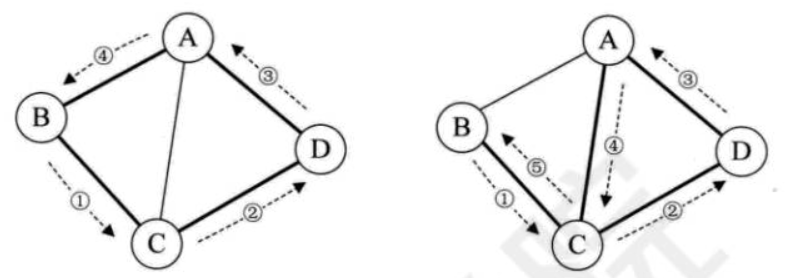
- 环:第一个顶点到最后一个顶点相同的路径称为回路或环(Cycle)
- 简单路径:序列中顶点不重复出现的路径称为简单路径
- 简单环:除了第一个顶点和最后一个顶点之外,其余顶点不重复出现的回路,称为简单回路或简单环
下图中两个图的粗线都构成环,左侧的环因第一个顶点和最后一个顶点都是B,且C、D、A没有重复出现,因此是一个简单环。而右侧的环,由于顶点C的重复,它就不是简单环了。
# 4. 连通图相关术语
连通图:在无向图G中,如果从顶点v到顶点v'有路径,则称v和v'是连通的。如果对于图中任意两个顶点vi、vj∈E,vi和vj都是连通的,则称G是连通图。
连通分量:无向图中的极大连通子图称为连通分量。
如下图:图一显然顶点A与顶点E或F就无路径,因此不能算是连通图,图二顶点A、B、C、D相互都是连通的,所以它本身是连通图。图一是一个无向非连通图。但是它有两个连通分量,即图二和图三。而图四,尽管是图一的子图,但是它却不满足连通子图的极大顶点数,因此它不是图一的无向图的连通分量。
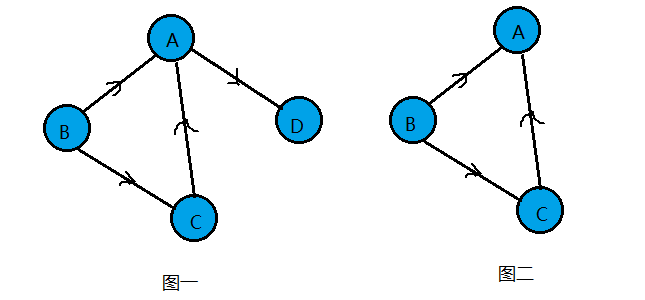
强连通图:在有向图G中,如果对于每一对点vi、vj∈E、vi≠vj,从vi到vj和从vj到vi都存在路径,则称G是强连通图。
强连通分量:有向图中的极大强连通子图称做有向图的强连通分量。
下图中,图一并不是强连通图,因为顶点A到顶点D存在路径,而D到A就在存在。图二就是强连通图,而且显然图二是图一的极大强连通子图,即是它的强连通分量。
生成树:一个连通图的生成树是一个极小的连通子图,它含有图中全部的n个顶点,但只有足以构成一棵树的n-1条边。
有向树:如果一个有向图恰有一个顶点的入度为0,其余顶点的入度均为1,则是一棵有向树。
对有向树的理解比较容易,所谓入度为0其实就相当于树中的根结点,其余顶点入度为1就是说树的非根结点的双亲只有一个
# 图的抽象数据类型
我们先定义一些图的基本操作:
/**
* 图的抽象数据类型
* @author hukai
*
* @param <T>
*/
public interface Graph<T> {
/**
* 在图G中增添新顶点vertex
* @param vertex
* @return 索引位置
*/
int insertVertex(T vertex);
/**
* 删除索引v处的顶点及其相关的弧
* @param v
*/
void deleteVertex(int v);
/**
* 在图G中增添孤<v,w>,若G是无向图,还需要增添对称弧<w,v>。如果是带权图,需要给定权值
* @param v 顶点v索引
* @param w 顶点w索引
* @param weight 权值
*/
void insertArc(int v,int w,int weight);
/**
* 在图G中删除孤<v,w>,若G是无向图,还需要删除对称弧<w,v>
* @param v
* @param w
*/
void deleteArc(int v,int w);
/**
* 若图G中存在顶点u,则返回图中的位置
* @param u
* @return
*/
int locateVertex(T u);
/**
* 返田图G中顶点v的值
* @param v 顶点v的索引
* @return
*/
T getVertex(int v);
/**
* 返回頂点v的一个邻接顶点,若頂点在G中无邻接顶点返田空
* @param v
* @return
*/
int firstAdjVex(int v);
/**
* 返回顶点v相对于顶点w的下一个邻接顶点,若w是v的最后一个顶点返回空
* @param v
* @param w
* @return
*/
int nextAdjVex(int v,int w);
/**
* 获取顶点总数
* @return
*/
int getVexNum();
/**
* 获取总边数。注意在无向图中对称的两条边视为同一条
* @return
*/
int getArcNum();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
# 图的存储结构
# 1. 邻接矩阵
图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。 一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
设图G(V,E)有n个顶点,则邻接矩阵是一个nxn的方阵,定义为:
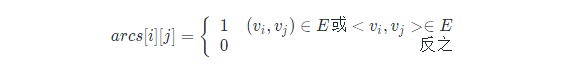
如下图就是一个无向图以邻接矩阵的表示形式:
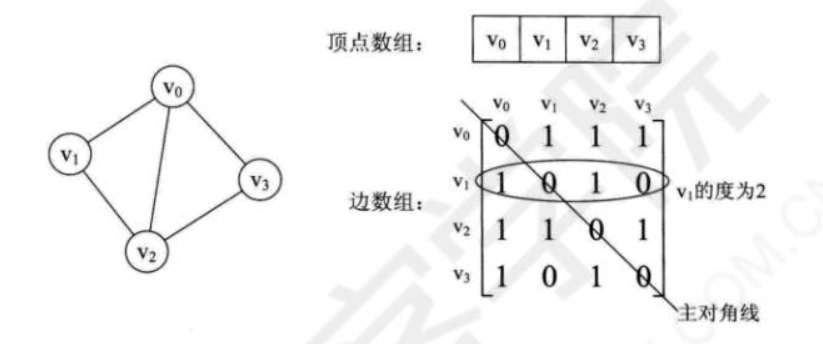
对于矩阵的主对角线的值全为0是因为不存在顶点到自身的边,比如v0到v0。并且由于是无向图,v1到v2的边存在,意味着v2到v1的边也存在。所以无向图的边数组是一个对称矩阵。
我们设边数组为arcs[][],根据这个矩阵,可以得到以下信息:
- arcs[i][j] == 1或arcs[j][i] == 1证明顶点vi和vj有边。
- 顶点vi的度,其实就是它在邻接矩阵中第i行或者第i列的元素之和。
- 求顶点vi的所有邻接点就是将矩阵中第i行元素扫描一遍。
再来看一个有向图的邻接矩阵表示:
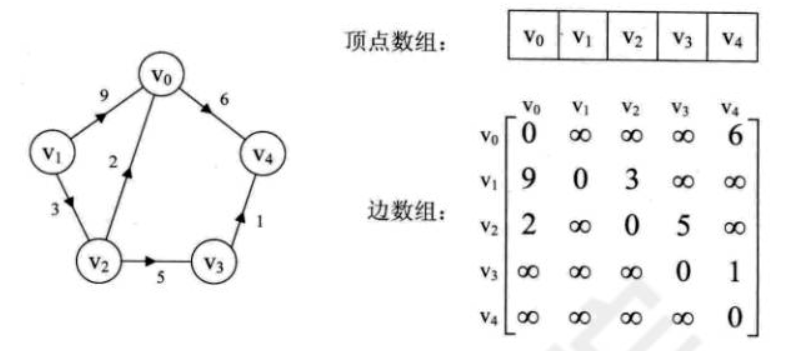
主对角线上数值依然为0。但因为是有向图,所以此矩阵并不对称。
有向图讲究入度与出度,顶点v1的入度为1,正好是第v1列各数之和。顶点v1的出度为2,即第v1行的各数之和。其他与无向图相同。
在图的术语中,我们提到了网的概念,也就是每条边上带有权的图叫做网。那么这些权值就需要存下来,如何处理这个矩阵来适应这个需求呢?
设图G(V,E)是网图,有n个顶点,则邻接矩阵是一个nxn的方阵,定义为:
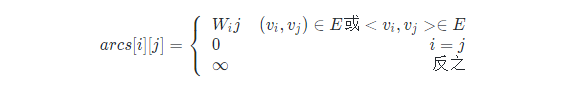
这里Wij表示(vi,vj)或<vi,vj>上的权值,∞表示一个计算机允许的、大于所有边上权值的值,也就是一个不可能的极限值。为什么不是0呢?因为权值Wij大多数情况下是正值,但个别时候可能就是0,甚至有可能是负值。因此必须要用一个不可能的值来代表不存在。在Java中我们就以Integer.MAX_VALUE来表示。
下图就是一个有向网图的邻接矩阵表示:
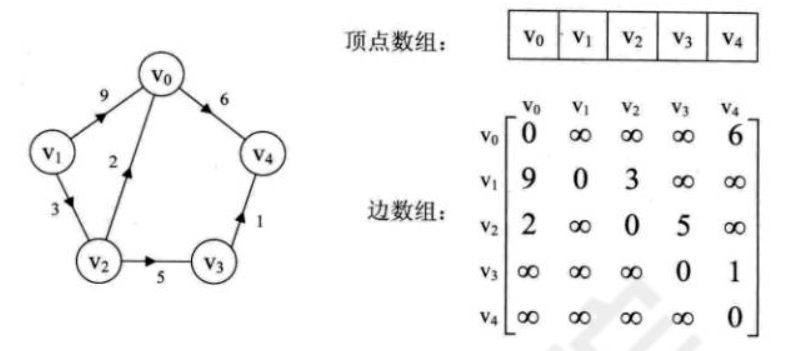
代码实现:
import java.util.Arrays;
/**
* 邻接矩阵
* @author hukai
*
*/
public class AdjacencyMatrixGraph<T> implements Graph<T> {
public final static int INFINITY = Integer.MAX_VALUE; // ∞
private boolean hasDirect,hasWeight; // 当前图是否有向,是否有权
private int vexNum, arcNum; // 顶点数和边数
private T[] vertexs; // 顶点数组
private int[][] arcs; // 邻接矩阵
/**
* 默认创建的是无向无权图,顶点最多为8个
*/
public AdjacencyMatrixGraph(){
this(false, false, 8);
}
@SuppressWarnings("unchecked")
public AdjacencyMatrixGraph(boolean hasDirect,boolean hasWeight,int maxVexNum){
this.hasDirect = hasDirect;
this.hasWeight = hasWeight;
this.vexNum = 0;
this.arcNum = 0;
this.vertexs = (T[]) new Object[maxVexNum];
this.arcs = new int[maxVexNum][maxVexNum];
// 初始化权值
if (hasWeight) {
for (int i = 0; i < maxVexNum; i++) {
for (int j = 0; j < maxVexNum; j++) {
if (i == j) {
arcs[i][j] = 0;
}else{
arcs[i][j] = INFINITY;
}
}
}
}
}
/**
* 在图G中增添新顶点vertex
*/
@Override
public int insertVertex(T vertex) {
if (vertex == null) return -1;
vertexs[vexNum++] = vertex;
return vexNum;
}
/**
* 在图G中增添孤,若G是无向图,还需要增添对称弧。如果是带权图,需要给定权值
*/
@Override
public void insertArc(int v, int w, int weight) {
checkIndex(v,w);
if (v == w) return;
// 如果不是带权图,权值为1
if (!hasWeight) weight = 1;
// 如果已经有路径了,不需要增加边数
if (!isConnected(v, w)) arcNum++;
arcs[v][w] = weight;
// 如果是无向图
if (!hasDirect) arcs[w][v] = weight;
}
@Override
public int locateVertex(T u) {
if (u == null) return -1;
for (int i = 0; i < vexNum; i++) {
if (vertexs[i].equals(u)) return i;
}
return -1;
}
@Override
public T getVertex(int v) {
// 索引越界
checkIndex(v);
return vertexs[v];
}
@Override
public int firstAdjVex(int v) {
// 索引越界
checkIndex(v);
for (int j = 0; j < vexNum; j++) {
if (isConnected(v, j)) return j;
}
return -1;
}
@Override
public int nextAdjVex(int v, int w) {
checkIndex(v,w);
for (int j = w+1; j < vexNum; j++) {
if (isConnected(v, j)) return j;
}
return -1;
}
/**
* 返回两个顶点之前是否连通
* @param i
* @param j
* @return
*/
private boolean isConnected(int i,int j){
// i=j为对角线的点
if (i == j) return false;
// 如果为不带权,非0即为连通;如果带权,非INFINITY才算连通
if (hasWeight) {
return arcs[i][j] != INFINITY;
}else{
return arcs[i][j] != 0;
}
}
/**
* 检查给定的索引是否越界
* @param index
* @return
*/
private void checkIndex(int...indexs){
for (int i = 0; i < indexs.length; i++) {
if (indexs[i] >= vexNum || indexs[i] < 0) throw new ArrayIndexOutOfBoundsException("索引越界");
}
}
@Override
public int getVexNum() {
return vexNum;
}
@Override
public int getArcNum() {
return arcNum;
}
//显示图对应的矩阵
@Override
public void showGraph() {
for(int[] link : arcs) {
System.out.println(Arrays.toString(link));
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
# 2. 邻接表
邻接矩阵是不错的一种图存储结构,但是我们也发现,对于边数相对顶点较少的图,这种结构是存在对存储空间的极大浪费的。
我们在树中谈存储结构时,讲到了一种孩子表示法,将结点存入数组,并对结点的孩子进行链式存储,不管有多少孩子,也不会存在空间浪费问题。这个思路同样适用于图的存储。我们把这种数组与链表相结合的存储方法称为邻接表(Adjacency List)。
处理办法为:
- 图中顶点用一个一维数组存储
- 图中每个顶点vi的所有邻接点构成一个线性表,由于邻接点的个数不定,所以用单链表存储。无向图称为顶点vi的边表,有向图则称为顶点vi作为弧尾的出边表。
下图所示的就是一个无向图的邻接表结构:
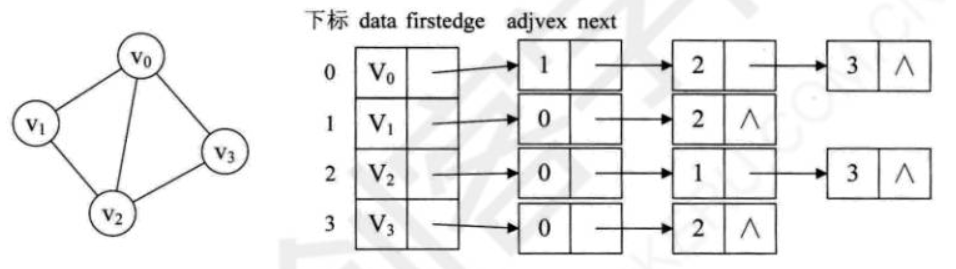
顶点表的各个结点由data和firstedge两个域表示,data是数据域,存储顶点的信息,firstedge是指针域,指向边表的第一个结点,即此顶点的第一个邻接点。边表结点由adjvex和next两个域组成,adjvex是邻接点域,存储某顶点的邻接点在顶点表中的下标,next则存储指向边表中下一个结点的指针。
根据这个思路,我们把代码写出来:
/**
* 邻接表
* @author hukai
*
* @param <T>
*/
public class AdjacencyListGraph<T> implements Graph<T> {
private boolean hasDirect,hasWeight; // 当前图是否有向,是否有权
private int vexNum, arcNum; // 顶点数和边数
private VexNode<T>[] vexNodes;// 顶点数组(也可以换成ArrayList或LinkedList)
public AdjacencyListGraph() {
this(false,false,8);
}
@SuppressWarnings("unchecked")
public AdjacencyListGraph(boolean hasDirect, boolean hasWeight,int maxVexNum) {
super();
this.hasDirect = hasDirect;
this.hasWeight = hasWeight;
this.vexNodes = new VexNode[maxVexNum];
this.vexNum = 0;
this.arcNum = 0;
}
@Override
public int insertVertex(T vertex) {
if (vertex == null) return -1;
VexNode<T> vexNode = new VexNode<T>(vertex);
vexNodes[vexNum++] = vexNode;
return vexNum;
}
@Override
public void insertArc(int v, int w, int weight) {
checkIndex(v,w);
if (v == w) return;
// 如果不是带权图,权值为1
if (!hasWeight) weight = 1;
// 如果已经有路径了,不需要增加边数
if (!isConnected(v, w)) arcNum++;
linkLast(vexNodes[v], new EdgeNode(w, weight));
// 如果是无向图
if (!hasDirect) linkLast(vexNodes[w], new EdgeNode(v, weight));
}
@Override
public int locateVertex(T u) {
if (u == null) return -1;
for (int i = 0; i < vexNum; i++) {
if (vexNodes[i].data.equals(u)) return i;
}
return -1;
}
@Override
public T getVertex(int v) {
// 索引越界
checkIndex(v);
return vexNodes[v].data;
}
@Override
public int firstAdjVex(int v) {
// 索引越界
checkIndex(v);
EdgeNode firstEdge = vexNodes[v].firstEdge;
return firstEdge == null ? -1 : firstEdge.adjvex;
}
@Override
public int nextAdjVex(int v, int w) {
checkIndex(v,w);
for (EdgeNode edgeNode = vexNodes[v].firstEdge;edgeNode != null;edgeNode = edgeNode.next) {
if (edgeNode.adjvex == w) {
return edgeNode.next == null ? -1 : edgeNode.next.adjvex;
}
}
return -1;
}
@Override
public int getVexNum() {
return vexNum;
}
@Override
public int getArcNum() {
return arcNum;
}
/**
* 将指定的元素追加到此列表的末尾
* @param newNode
* @param vexNodes
*
* @param e
*/
void linkLast(VexNode<T> vexNodes, EdgeNode newNode) {
EdgeNode edgeNode = vexNodes.firstEdge;
if (edgeNode == null) {
vexNodes.firstEdge = newNode;
return;
}
while(edgeNode.next != null){
edgeNode = edgeNode.next;
}
edgeNode.next = newNode;
}
/**
* 返回两个顶点之前是否连通
* @param i
* @param j
* @return
*/
private boolean isConnected(int i,int j){
for(EdgeNode edgeNode = vexNodes[i].firstEdge; edgeNode != null; edgeNode = edgeNode.next){
if (edgeNode.adjvex == j) return true;
}
return false;
}
/**
* 检查给定的索引是否越界
* @param index
* @return
*/
private void checkIndex(int...indexs){
for (int i = 0; i < indexs.length; i++) {
if (indexs[i] >= vexNum || indexs[i] < 0) throw new ArrayIndexOutOfBoundsException("索引越界");
}
}
/**
* 边表结点
*/
private static class EdgeNode{
int adjvex; // 邻接点在顶点表中的下标
int weight; // 权重
EdgeNode next; // 指向边表中下一个结点的指针
EdgeNode(int adjvex,int weight){
this.adjvex = adjvex;
this.weight = weight;
}
}
/**
* 顶点数组结点
*/
private static class VexNode<T>{
T data; // 数据
EdgeNode firstEdge; // 边表的第一个结点
public VexNode(T data) {
this.data = data;
}
}
@Override
public void showGraph() {
for (int i = 0; i < vexNodes.length; i++) {
StringBuilder sb = new StringBuilder();
sb.append(i).append("[").append(vexNodes[i].data).append("]");
EdgeNode edgeNode = vexNodes[i].firstEdge;
while (edgeNode != null) {
sb.append("→").append(edgeNode.adjvex);
edgeNode = edgeNode.next;
}
System.out.println(sb.toString());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
若是有向图,邻接表结构是类似的,但要注意的是有向图由于有方向,我们是以顶点为弧尾来存储边表的,这样很容易就可以得到每个顶点的出度。但也有时为了便于确定顶点的入度或以顶点为弧头的弧,我们可以建立一个有向图的逆邻接表,即对毎个顶点vi都建立一个链接为vi弧头的表:
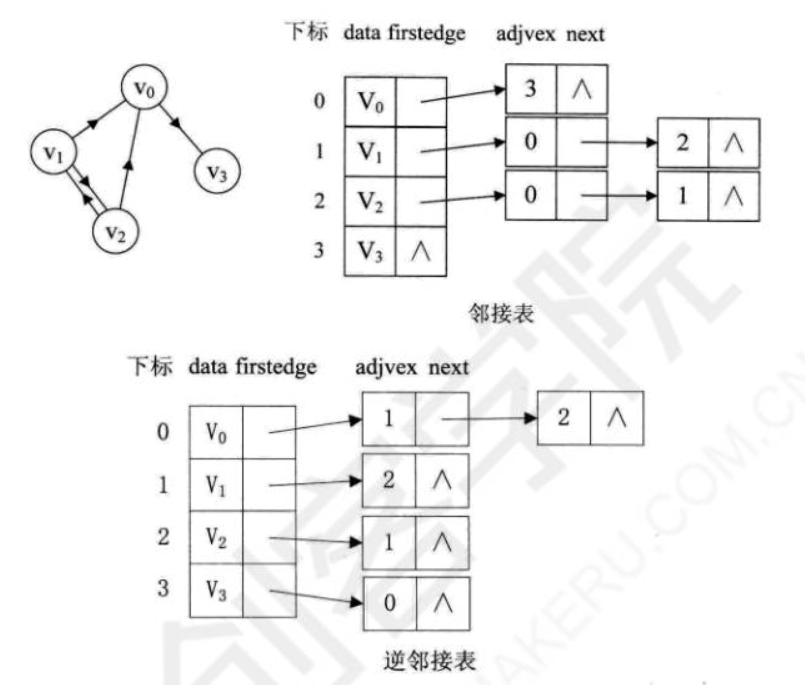
此时我们很容易就可以算出某个顶点的入度或出度是多少,判断两顶点是否存在弧也很容易实现。
对于带权值的网图,可以在边表结点定义中再増加一个weight的数据域,在此不作详述。
# 3. 十字链表
对于有向图来说,邻接表是有缺陷的。关心了出度问题,想了解入度就必须要遍历整个图才能知道,反之,逆邻接表解决了入度却不了解出度的情况。
我们可以把邻接表与逆邻接表结合起来,就能解决这个问题。这个存储方法就叫十字链表。
我们重新定义顶点表结点结构:
/**
* 顶点表结点
*/
private static class VexNode<T>{
T data; // 数据
EdgeNode firstIn; // 入边表中第一个结点
EdgeNode firstOut;// 出边表头指针
public VexNode(T data) {
this.data = data;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
其中firstIn表示入边表头指针,指向该顶点的入边表中第一个结点,firstOut表示出边表头指针,指向该顶点的出边表中的第一个结点。
重新定义的边表结点结构:
/**
* 边表结点
*/
private static class EdgeNode{
//A→B A为起点tailVex,B为终点headVex
int tailVex; // 弧起点在顶点表的下标 A
int headVex; // 弧终点在顶点表中的下 B
EdgeNode tailLink;// 指向起点相同的下一条边.起点为A
EdgeNode headLink;// 指向终点相同的下一条边.终点为B
int weight; // 权重
public EdgeNode(int tailVex, int headVex, int weight) {
this.tailVex = tailVex;
this.headVex = headVex;
this.weight = weight;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
我们来看一个十字链表的实例:
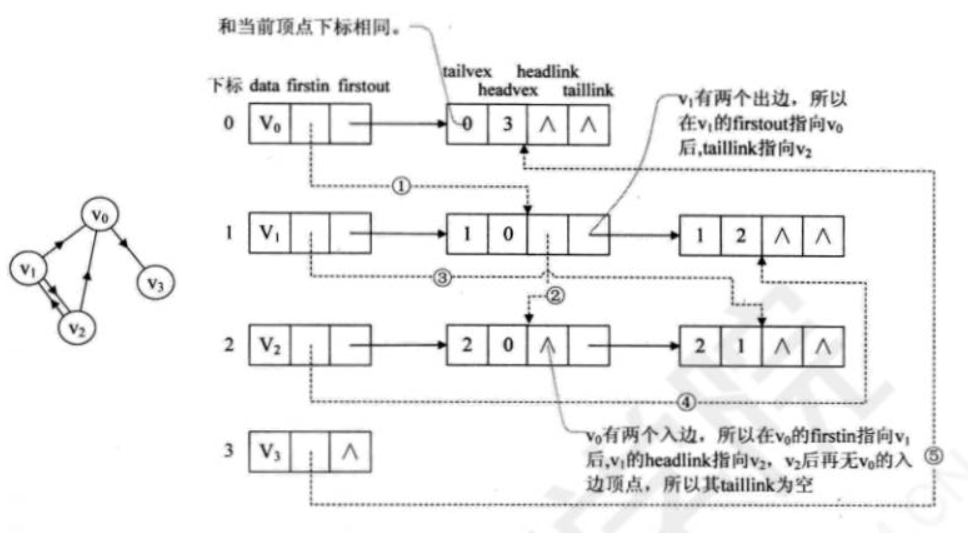
虚线箭头其实就是此图的逆邻接表表示。对于v0来说,它有两个顶点v1和v2的入边。因此v0的firstln指向顶点v1的边表结点中headvex为0的结点,接着由入边结点的headlink指向下个入边顶点v2。
完整实现:
import java.util.ArrayList;
import java.util.List;
/**
* 十字链表
* @author hukai
*
* @param <T>
*/
public class OrthogonalListGraph<T> implements Graph<T> {
private int arcNum; // 边数
private List<VexNode<T>> vexNodes;
public OrthogonalListGraph() {
this.vexNodes = new ArrayList<VexNode<T>>();
}
@Override
public int insertVertex(T vertex) {
if (vertex == null) return -1;
VexNode<T> vexNode = new VexNode<T>(vertex);
vexNodes.add(vexNode);
return vexNodes.size() - 1;
}
@Override
public void insertArc(int v, int w, int weight) {
checkIndex(v,w);
if (v == w) return;
// 如果已经有路径了,不需要新增
if (isConnected(v, w)) return;
EdgeNode edgeNode = new EdgeNode(v, w);
VexNode<T> outVexNode = vexNodes.get(v);
VexNode<T> inVexNode = vexNodes.get(w);
// 添加出路径
linkedLast(outVexNode,inVexNode,edgeNode);
arcNum++;
}
private void linkedLast(VexNode<T> outVexNode, VexNode<T> inVexNode, EdgeNode edgeNode) {
EdgeNode outEdgeNode = outVexNode.firstOut;
if (outEdgeNode == null) {
outVexNode.firstOut = edgeNode;
}else{
while (outEdgeNode.tailLink != null) {
outEdgeNode = outEdgeNode.tailLink;
}
outEdgeNode.tailLink = edgeNode;
}
EdgeNode inEdgeNode = inVexNode.firstIn;
if (inEdgeNode == null) {
inVexNode.firstIn = edgeNode;
}else{
while (inEdgeNode.headLink != null){
inEdgeNode = inEdgeNode.headLink;
}
inEdgeNode.headLink = edgeNode;
}
}
@Override
public int locateVertex(T u) {
if (u == null) return -1;
for (int i = 0; i < vexNodes.size(); i++) {
if (vexNodes.get(i).data.equals(u)) return i;
}
return -1;
}
@Override
public T getVertex(int v) {
// 索引越界
checkIndex(v);
return vexNodes.get(v).data;
}
@Override
public int firstAdjVex(int v) {
// 索引越界
checkIndex(v);
EdgeNode firstOut = vexNodes.get(v).firstOut;
if (firstOut != null) {
return firstOut.headVex;
}
return -1;
}
@Override
public int getVexNum() {
return vexNodes.size();
}
@Override
public int getArcNum() {
return arcNum;
}
/**
* 是否连通
* @param i
* @param j
* @return
*/
private boolean isConnected(int i, int j){
VexNode<T> vexNode = vexNodes.get(i);
for (EdgeNode edgeNode = vexNode.firstOut; edgeNode != null; edgeNode = edgeNode.tailLink) {
if (edgeNode.headVex == j) return true;
}
return false;
}
/**
* 检查给定的索引是否越界
* @param index
* @return
*/
private void checkIndex(int...indexs){
for (int i = 0; i < indexs.length; i++) {
if (indexs[i] >= vexNodes.size() || indexs[i] < 0) throw new ArrayIndexOutOfBoundsException("索引越界");
}
}
/**
* 边表结点
*/
private static class EdgeNode{
//A→B A为起点tailVex,B为终点headVex
int tailVex; // 弧起点在顶点表的下标 A
int headVex; // 弧终点在顶点表中的下 B
EdgeNode tailLink;// 指向起点相同的下一条边.起点为A
EdgeNode headLink;// 指向终点相同的下一条边.终点为B
public EdgeNode(int tailVex, int headVex) {
this.tailVex = tailVex;
this.headVex = headVex;
}
}
/**
* 顶点数组结点
*/
private static class VexNode<T>{
T data; // 数据
EdgeNode firstIn; // 入边表中第一个结点
EdgeNode firstOut;// 出边表头指针
public VexNode(T data) {
this.data = data;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
十字链表的好处就是因为把邻接表和逆邻接表整合在了一起,这样既容易找到以点vi为尾的弧,也容易找到以点vi为头的弧,因而容易求得顶点的出度和入度。而且它除了结构复杂一点外,其实创建图算法的时间复杂度是和邻接表相同的,因此,在有向图的应用中,十字链表是非常好的数据结构模型。
# 邻接多重表
上面说到的十字链表,其实是邻接表对于有向图的优化存倚结构,那对于无向图的邻接表能不能优化一下呢?
如果我们在无向图的应用中,关注的重点是顶点,那么邻接表是不错的选择,但如果我们更关注边的操作,比如对已访问过的边做标记,删除某一条边等操作,那就意味着,需要找到这条边的两个边表结点进行操作,这其实还是比较麻烦的。
因此,我们也仿照十字链表的方式,对边表结点的结构进行一些改造,也许就可以避免刚才提到的问题。
我们重新定义的边表结点结构,如图:

其中ivex和jvex是与某条边依附的两个顶点在顶点表中下标。ilink指向依附顶点ivex的下一条边,jlink指向依附顶点jvex的下一条边。这就是邻接多重表结构。
我们来绘制一个无向图的邻接多重表结构:
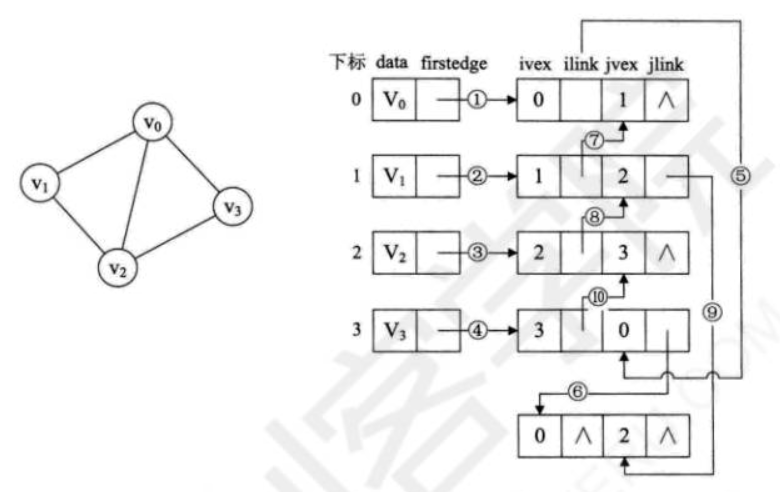
到这里,大家应该可以明白,邻接多重表与邻接表的差別,仅仅是在于同一条边在邻接表中用两个结点表示,而在邻接多重表中只有一个结点。这样对边的操作就方便多了。代码略过。
# 边集数组
边集数组是由两个一维数组构成。一个是存储顶点的倌息;另一个是存储边的信息,这个边数组毎个数据元素由一条边的起点下标(begin)、终点下标(end)和权(weight)组成。
显然边集数组关注的是边的集合,在边集数组中要查找一个顶点的度需要扫描整个边数组,效率并不髙。因此它更适合对边依次进行处理的操作,而不适合对顶点相关的操作。
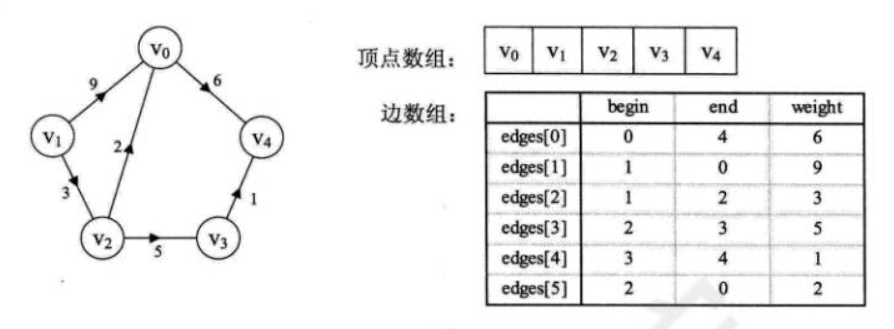
边数组中begin是存储起点下标,end是存储终点下标,weight是存储权值。