 图的遍历
图的遍历
# 定义
从图中某一顶点出发访遍图中其余顶点,且使每一个顶点仅被访问一次,这个访问的过程叫做图的遍历(Traversing Graph)
由于图的任一顶点都可能和其余的所有顶点相邻接,极有可能存在沿着某条路径搜索后,又回到原顶点,而有些顶点却还没有遍历到的情况。因此我们需要在遍历过程中把访问过的顶点打上标记,具体办法是设置一个访问数组visited[n]。
对于图的遍历来说,通常有两种遍历次序方案:深度优先遍历和广度优先遍历。Guava中的Graph模块已对这两种图的遍历算法进行了实现,且其代码是我所见过最完美的实现了。有兴趣可以研究一下,本文只是简单实现这两种遍历。
# 深度优先遍历
# 1. 基本思想
深度优先遍历(Depth First Search),也有称为深度优先搜索,简称为DFS
深度优先搜索遍历类似于树的前序遍历,是树的前序遍历的推广。
假设初始状态是图中的所有顶点都没有被访问,则深度优先搜索可以从图中某个顶点v出发,访问此顶点,然后依次从v的未被访问的邻接点出发深度优先遍历图,直至图中所有和v有路径相通的顶点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。显然,这是一个递归的过程。
算法描述总结如下:
- 访问初始结点v,并标记结点v为已访问;
- 查找结点v的第一个邻接结点w;
- 若w存在,则继续执行4。如果w不存在,则回到第1步,将从v的下一个结点继续;
- 若w未被访问,对w进行深度优先遍历递归(即把w当做另一个v,然后进行步骤123)。若w已被访问,查找结点v的w邻接结点的下一个邻接结点,转到步骤3;
# 2. 实例演示
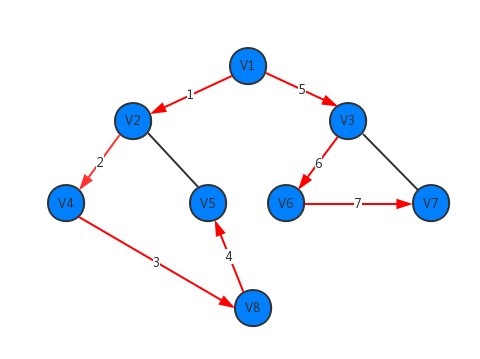
下面演示对示例图的深度优先遍历:
- 假设从起始点v1开始遍历,在访问了v1后,选择其邻接点v2;
- v2未曾访问过,则从v2出发进行深度优先遍历;
- 依次类推,接着从v4、v8、v5出发进行遍历;
- 在访问了v5后,由于v5的邻接点都已被访问,则遍历回退到v8。同样的理由,继续回退到v4、v2直至v1;
- v1的另一个邻接点v3未被访问,则遍历又从v1到v3,再继续进行下去;
- 到节点的线性顺序为:v1 -> v2 -> v4 -> v8 -> v5 -> v3 -> v6 -> v7。即示例图中红色箭头线为其深度优先遍历顺序
# 3. 代码实现
我们需要定义一个标记数组,用于标记顶点是否已经被访问过了。下面的代码是基于上篇博文中的邻接矩阵的实现:
private boolean[] isVisited; // 标记数组。用于标记顶点是否已被访问
/**
* 深度优先遍历递归算法
* @param isVisited
* @param v
*/
private void dfs(boolean[] isVisited,int v){
//首先我们访问该结点,输出
System.out.print(this.getVertex(v) + "\t");
//将结点设置为已经访问
isVisited[v] = true;
//查找结点i的第一个邻接结点w
int w = this.firstAdjVex(v);
while(w != -1) {
if(!isVisited[w]) {
dfs(isVisited, w);
}
//如果w结点已经被访问过
w = nextAdjVex(v, w);
}
}
/**
* 深度优先遍历
*/
public void deepFirstSearch(){
isVisited = new boolean[vexNum];
//遍历所有的结点,进行dfs[回溯]
for(int i = 0; i < vexNum; i++) {
if(!isVisited[i]) {
dfs(isVisited, i);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
由于我们已经封装好了获取邻接点的相关方法,所以代码上邻接矩阵和邻接表的深度优先遍历实现是相同的。
# 广度优先遍历
# 1. 基本思想
广度优先遍历(Breadth First Search),又称为广度优先搜索,简称BFS
如果说图的深度优先遍历类似树的前序遍历,那么图的广度优先遍历就类似于树的层序遍历了。
假设从图中某个顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,然后分别从这些邻接点出发并依次访问它们的邻接点,并使“先被访问的顶点邻接点”先于“后被访问的顶点的邻接点”被访问,直到图中所有所有已被访问的顶点的邻接点都被访问到。若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点重复上述过程,直至图中所有顶点均被访问到为止。
算法描述总结如下:
- 访问初始结点v并标记结点v为已访问,将结点v入队列;
- 当队列非空时,继续执行,否则算法结束;
- 出队列,取得队头结点u,查找结点u的第一个邻接结点w;若结点u的邻接结点w不存在,则转到步骤3,否则循环执行以下三个步骤;
- 若结点w尚未被访问,则访问结点w并标记为已访问;
- 结点w入队列;
- 查找结点u的继w邻接结点后的下一个邻接结点w,转到步骤4;
# 2. 实例演示
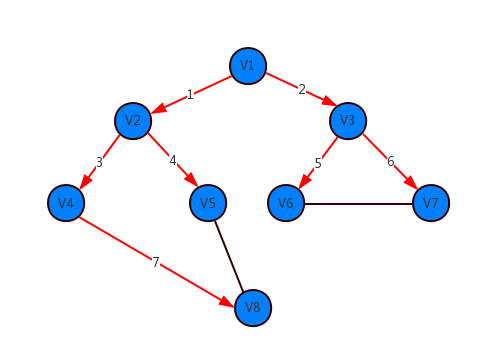
下面演示对示例图的广度优先遍历:假设从起始点v1开始遍历,首先访问v1和v1的邻接点v2和v3,然后依次访问v2的邻接点v4和v5,及v3的邻接点v6和v7,最后访问v4的邻接点v8。于是得到节点的线性遍历顺序为:v1 -> v2 -> v3 -> v4 -> v5 -> v6 -> v7 -> v8,即示例图中红色箭头线为其广度优先遍历顺序。
# 3. 代码实现
以下是邻接矩阵结构的广度优先遍历算法,邻接表的代码类似,在此不做详述。
/**
* 广度优先遍历算法
* @param isVisited
* @param v
*/
private void bfs(boolean[] isVisited, int v){
//表示队列的头结点对应下标及邻接结点下标
int head,next;
Queue<Integer> queue = new ArrayDeque<>();
//访问结点,输出结点信息
System.out.print(this.getVertex(v) + "\t");
//标记为已访问
isVisited[v] = true;
//将结点入队
queue.offer(v);
while(!queue.isEmpty()) {
// 取出队列的头结点下标
head = queue.poll();
//得到第一个邻接结点的下标
next = this.firstAdjVex(head);
while(next != -1) {//找到
//是否访问过
if(!isVisited[next]) {
System.out.print(this.getVertex(next) + "\t");
//标记已经访问
isVisited[next] = true;
//入队
queue.offer(next);
}
next = this.nextAdjVex(head, next);
}
}
}
/**
* 广度优先遍历
*/
public void breadthFirstSearch(){
isVisited = new boolean[vexNum];
//遍历所有的结点,进行dfs[回溯]
for(int i = 0; i < vexNum; i++) {
if(!isVisited[i]) {
bfs(isVisited, i);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 总结
对比图的深度优先遍历与广度优先遍历算法,你会发现,它们在时间复杂度上是一样的,不同之处仅仅在于对顶点访问的顺序不同。可见两者在全图遍历上是没有优劣之分的,只是视不同的情况选择不同的算法。
深度优先更适合目标比较明确,以找到目标为主要目的的情况,而广度优先更适合在不断扩大遍历范围时找到相对最优解的情况。