 链表
链表
# 线性表的链式存储实现
# 1. 单链表的定义
链表是采用链式存储方式存储的线性表,链表中每一个结点中包含存放数据元素值的数据域和存放逻辑上相邻结点的指针域。
示例中的结点只包含一个指针域,称为单链表(Single Linked List)
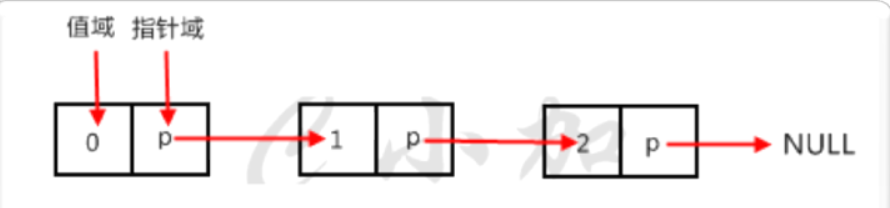
以线性表中的第一个数据元素的存储地址作为线性表的起始地址,称为线性表的头指针。通过头指针(head)来唯一标识一个链表。
有时,我们为了更加方便地对链表进行操作,会在单链表的第一个结点前附设一个结点,称为头结点。头结点的指针域存储指向第一个结点的指针,如图:
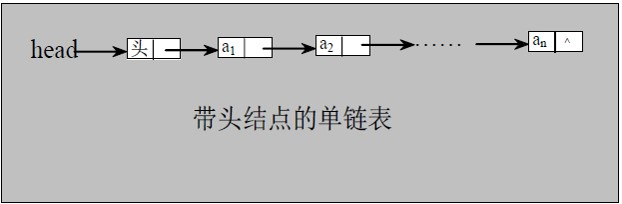
单链表中的最后一个节点没有后继,指针域为空指针(null),称为尾结点。
# 2. 链式存储的特点
不需要预先分配存储空间,动态分配存储空间,存储密度较低
无法随机查询,需要从头遍历来查找元素。时间复杂度O(n)
便于进行数据的插入和删除。时间复杂度O(1)
# 3. 单链表的结构类描述
JDK中有LinkedList很好的实现了链式存储,使用的是双向链表,关于链表后续会单独讲解,下面模仿LinkedList并使用单链表实现线性表的链式存储结构:
/**
* 线性表的链式存储实现(单链表)
*
*/
public class SingleLinkedList<E> implements MyList<E> {
/**
* 所包含的节点个数
*/
private int size = 0;
/**
* 头节点
*/
private Node<E> first;
/**
* 尾节点
*/
private Node<E> last;
public SingleLinkedList() {
}
@Override
public void clear() {
for (Node<E> x = first; x != null;) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x = next;
}
first = last = null;
size = 0;
}
/**
* 返回此列表中的元素数
*/
@Override
public int size() {
return size;
}
/**
* 返回此列表是否为空
*/
@Override
public boolean isEmpty() {
return size == 0;
}
@Override
public void add(E elem) {
linkLast(elem);
}
/**
* 根据指定索引返回数据
*/
@Override
public void insert(int index, E elem) {
checkPositionIndex(index);// 检查索引是否处于[0-size]之间
if (index == size) {
linkLast(elem);
} else {
linkBefore(elem, index);
}
}
@Override
public E get(int index) {
// 检查index范围是否在size之内
checkElementIndex(index);
// 调用Node(index)去找到index对应的node然后返回它的值
return node(index).item;
}
@Override
public E remove(int index) {
Node<E> x = node(index);
final E element = x.item;
final Node<E> next = x.next;// 得到后继节点
// 删除前驱指针
if (index == 0) {
first = next;// 如果删除的节点是头节点,令头节点指向该节点的后继节点
} else {
Node<E> prev = node(index - 1);
prev.next = next;// 将前驱节点的后继节点指向后继节点
}
// 删除后继指针
if (next == null) {
Node<E> prev = node(index - 1);
last = prev;// 如果删除的节点是尾节点,令尾节点指向该节点的前驱节点
} else {
x.next = null;
}
return element;
}
@Override
public int indexOf(E elem) {
int index = 0;
if (elem == null) {
// 从头遍历
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (elem.equals(x.item))
return index;
index++;
}
}
return index;
}
/**
* 将指定的元素追加到此列表的末尾
*
* @param e
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<E>(e, null);
last = newNode;// 新建节点
// 如果原尾节点为空,则当前链表为空链表,
if (l == null) {
// 此时头尾节点都应该为当前添加的节点
first = newNode;
} else {
l.next = newNode;// 指向后继元素也就是指向下一个元素
}
size++;
}
/**
* 将指定的元素插入到此列表指定索引位置
*
* @param e
* @param prev
*/
void linkBefore(E e, int index) {
// 插入到头节点
if (index == 0) {
final Node<E> newNode = new Node<>(e, first);
first = newNode;
} else {
final Node<E> prev = node(index - 1);
final Node<E> newNode = new Node<>(e, prev.next);
prev.next = newNode;
}
size++;
}
/**
* 根据索引找到对应节点
*/
Node<E> node(int index) {
// 从头结点开始找
Node<E> x = first;
for (int i = 0; i < index; i++) {
x = x.next;
}
return x;
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + size);
}
/**
* 检查索引是否处于[0-size]之间
*
* @param index
*/
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + size);
}
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}
/**
* Node内部类
*/
private static class Node<E> {
E item;
Node<E> next;
Node(E element, Node<E> next) {
this.item = element;
this.next = next;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
# 单链表结构与顺序存储结构对比
| 存储结构 | 存储分配方式 | 时间性能 | 空间性能 |
|---|---|---|---|
| 顺序存储 | 连续的存储单元 | 查找O(1),插入和删除O(n) | 需要预先分配存储空间,分大了浪费,分小了易发生上溢 |
| 单链表 | 任意的存储单元 | 查找O(n),插入和删除O(1) | 不需要预先分配存储空间,元素个数也不受限制 |
通过对比,得出结论:
- 若线性表需要频繁查找,很少进行插入和删除操作,宜采用顺序存储结构。若要频繁插入和删除,宜采用单链表结构。
- 当线性表中的元素个数变化较大或者根本不知道用多大,最好采用单链表结构,这样可以不考虑存储空间大小问题。而如果实现知道线性表大致长度,用顺序存储效率会高很多。
# 其他链表
# 1. 循环链表
将单链表中终端节点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的链表称为单循环链表,简称循环链表。
如图:

单链表中,从一已知结点出发,只能访问到该结点及其后续结点,无法找到该结点之前的其它结点。而在单循环链表中,从任一结点出发都可访问到表中所有结点,这一优点使某些运算在单循环链表上易于实现。
其实循环链表和单链表的主要差异就在于循环的判断条件上,原来是判断p.next是不是为空,现在则是p.next是否指向头结点。
# 2. 双向链表
在单链表中,有了next指针,这就使得我们查找下一结点的时间复杂度为O(1)。可是如果我们要查找的是上一节点的话,那最坏情况的时间复杂度就是O(n)了,因为每次我们都要从头开始查找。
为了克服这一缺点,我们引入双向链表: 双向链表是在单链表的每个节点中,再设置一个指向其前驱节点的指针域。如图:
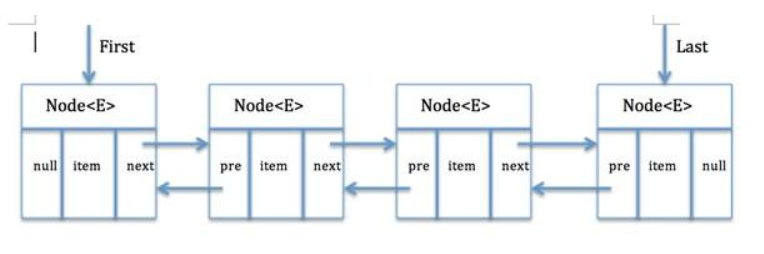
相对于单链表,在找当前节点的前一节点时比较方便,由于他良好的对称性,使得对某个节点前后节点的操作带来了方便,提高了算法的时间性能。同时单向链表不能自我删除,需要靠辅助节点,而双向链表,则可以自我删除。但由于每个节点都需要记录两份指针,所以空间占用略多一点。说白了就是用空间换时间。
# 3. 双循环链表
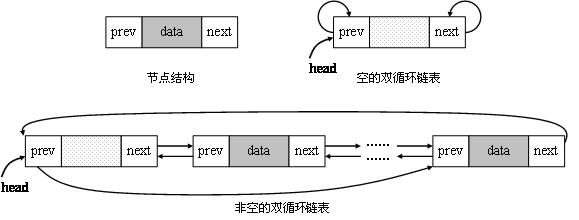
双循环链表结合了双链表和循环链表的特定,从双循环链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点,其结构如下图所示:
# 4. 静态链表
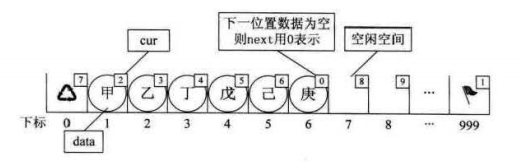
对于没有指针的编程语言,可以用数组替代指针,来描述链表。让数组的每个元素由data和cur两部分组成,其中cur相当于链表的next指针,这种用数组描述的链表叫做静态链表,这种描述方法叫做游标实现法。我们对数组的第一个和最后一个元素做特殊处理,不存数据。让数组的第一个元素cur存放第一个备用元素(未被占用的元素)下标,而数组的最后一个元素cur存放第一个有值的元素下标,相当于头结点作用。
空的静态链表如下图:
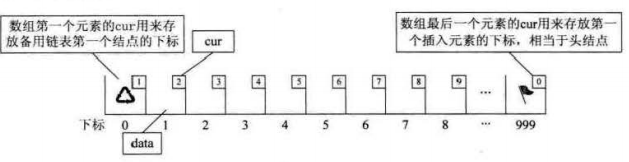
当存放入一些数据时("甲""乙""丁""戊""己""庚"),静态链表为:
← 线性表的顺序存储结构 栈→