 哈希表
哈希表
# 哈希表概述
# 1. 什么是哈希表
哈希表也称散列表,是一种根据关键字值(key - value)而直接进行访问的数据结构。
它基于数组,通过把关键字映射到数组的某个下标来加快查找速度,但是又和数组、链表、树等数据结构不同,在这些数据结构中查找某个关键字,通常要遍历整个数据结构,也就是O(n)的时间级,但是对于哈希表来说,只是O(1)的时间级。
# 2. 哈希函数
说到哈希表,不得不提到散列技术。散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f (key)。即:地址index=f(key)
我们把这种对应关系f称为散列函数,又称为哈希(Hash)函数。按这个思想,采用散列技术将记录存锗在一块连续的存储空间中,这块连续存储空间称为散列表或哈希表(Hashtable)。那么关键字对应的记录存储位置我们称为散列地址。
# 3. 散列表查找步骤
整个散列过程其实就是两步:
- 在存储时,通过散列函数计算记录的散列地址,并按此散列地址存储该记录
- 当査找记录时,我们通过同样的散列函数计算记录的散列地址,按此散列地址访问该记录
# 4. 冲突
在理想的情况下,每一个关键字,通过散列函数计算出来的地址都是不一样的,可现实中,这只是一个理想。我们时常会碰到两个关键字key1,key2(但是却有f (key1) = f(key2),这种现象我们称为冲突(collision),并把key1,和key2称为这个散列函数的同义词(synonym)。
# 散列函数的构造方法
散列函数的构造需要遵循下面两个原则:
- 计算简单
- 散列地址分布均匀
根据前人经验,统计出下面几种常用hash函数的构造方法。
# 1. 直接定址法
以取关键字的某个线性函败值为散列地址,如 f(key) = a * key + b 。其中,a、b均为常数。
这样的散列函数优点就是简单、均匀,也不会产生冲突,但问题是这需要事先知道关键字的分布情况,适合査找表较小且连续的情况。由于这样的限制,在现实应用中,此方法虽然简单,但却并不常用。
# 2. 数字分析法
如果我们的关键字是位数较多的数字,比如手机号:136xxxx5708。其中前三位是接入号,一般对应不同运营商公司的子品牌,比如136是移动神州行,中间四位是HLR识别号,表示用户号的归属地;后四位才是真正的用户号。
若我们现在要存储某家公司员工登记表,如果用手机号作为关键字,那么极有可能前7位都是相同的。那么我们选择后面的四位成为散列地址就是不错的选择。如果 这样的抽取工作还是容易出现冲突问题,还可以对抽取出来的数字再进行反转等各种处理方式,总的目的就是为了提供一个散列函数,能够合理地将关键字分配到散列表的各位置。
数字分析法通常适合处理关键字位数比较大的悄况,如果事先知道关键字的分布且关键字的若干位分布较均匀,就可以考虑用这个方法。
# 3. 平方取中法
这个方法计算很简单,假设关键字是1234,那么它的平方就是1522756,再抽取中间的3位就是227,用做散列地址。再比如关键字是4321,那么它的平方就是 18671041,抽取中间的3位就可以是671,也可以是710,用做散列地址。
平方取中法比较适合于不知道关键字的分布,而位数又不是很大的悄况。
# 4. 折叠法
折叠法是将关键字从左到右分割成位数相等的几部分(注意最后一部分位数不够时可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
比如我们的关键字是9876543210,散列表表长为三位,我们将它分为四组,987|654|321|0,然后将它们叠加求和987+654+321+0=1962,再求后3位得到散列地址为962。
折叠法事先不需要知道关键字的分布,适合关键字位数较多的情况。
# 5. 除留余数法
此方法为最常用的构造散列函数方法。对于散列表长为m的散列函数公式为:
f(key) = key mod p ( p<=m )
mod是取模(求余数)的意思。亊实上,这方法不仅可以对关键字直接取模,也可在折叠、平方取中后再取模。
很显然,本方法的关键就在于选择合适的P,P如果选得不好,就可能会容易产生同义词。
根据前辈们的经验,若散列表表长为m,通常p为小于或等于表长(最好接近m)的最小质数或不包含小于20质因子的合数。
# 6. 随机数法
选择一个随机数,取关键字的随机函数值为它的散列地址。也就是:
f(key) = random(key)
这里random是随机函数,当关键字的长度不等时,采用这个方法构造散列函数是比较合适的。
# 处理散列冲突的方法
# 1. 开放定址法
所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
它的公式是:
fi(key) = ( f(key) + di ) mod m
其中:f(key)为哈希函数;m为哈希表表长;di为增量序列,有以下3中取法:
- di = 1,2,3,…,m-1。称为线性探测再散列
- di = 1²,-1²,2²,-2²,...,±k²,(k<= m/2)称为二次探测再散列
- di = 伪随机数序列,称为伪随机数探测再散列
例如:在长度为12的哈希表中插入关键字为38的记录:
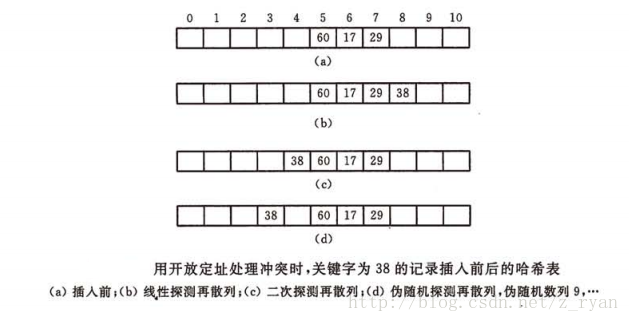
(b)中计算f(38)=5,而下标为5的位置已经被占了。于是带入公式fi(38) = (f(38) + 3) mod 11 = 8。从这个例子我们也看到,我们在解决冲突的时候,还会碰到本来都不是同义词却需要争夺一个地址的情况,我们称这种现象为堆积。
但是,用线探测再散列处理冲突可以保证:只要哈希表未填满,总能找到一个不发生冲突的地方。
# 2. 再哈希法
对于我们的散列表来说,我们事先准备多个散列函数。
fi(key) = RHi(key) (i=1,2,3...,k)
这里RHi就是不同的散列函数。毎当发生散列地址冲突时,就换一个散列函数计算,相信总会有一 个可以把冲突解决掉。这种方法能够使得关键字不产生聚集,当然,相应地也増加了计算的时间。
# 3. 链地址法
将所有关键字为同义字的记录存储在一个单链表中,我们称这种单链表为同义词子表,散列表中存储同义词子表的头指针。 Java中的HashMap就是这么干的。
如关键字集合为{19,14,23,01,68,20,84,27,55,11,10,79},按哈希函数f(key) = key mod 13
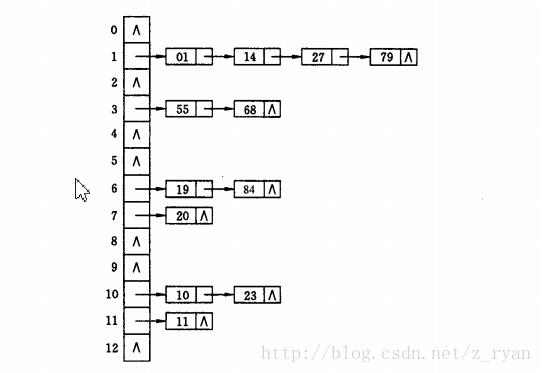
链地址法对于可能会造成很多冲突的散列函数来说,提供了绝不会出现找不到地址的保障。当然,这也就带来了査找时需要遍历单链表的性能损耗。
# 4. 公共溢出区法
即设立两个查找表:基础表和溢出表。将所有关键字通过哈希函数计算出相应的地址。然后将未发生冲突的关键字放入相应的基础表中,一旦发生冲突,就将其依次放入溢出表中即可。
在査找时,对给定值通过散列函数计算出散列地址后,先与基本表的相应位置进行比对,如果相等,则査找成功;如果不相等,则到溢出表去进行顺序査找。
如果相对于基本表而言,有冲突的数据很少的情况下,公共溢出区的结构对査找性能来说还是非常髙的。
# 哈希表实现
要想实现一个查找性能优越的哈希表,以下几点因素至关重要:
- 散列函数是否均匀(直接影响着出现冲突的频繁程度)
- 处理冲突的方法(冲突是不可避免的,但处理冲突的方法不同,会使得平均査找长度不同。尽可能不要产生堆积,链地址法比较实用)
- 散列表的装填因子(所谓的装填因子α=填入表中的记录个数/散列表长度。当填入表中的记录越多,α就越大,产生冲突的可能性就越大,当α过大时,我们就应该考虑给数组扩容了,否则冲突的几率会大大提高)
下面我们参照Java中的HashMap实现一个简单的哈希表。
# 1. 内部结点类实现
由于我们使用的是链地址法解决冲突,所以需要构建单链表结构:
public interface BaseEntry <K,V>{
K getKey();//获取键
V getValue();//获取值
}
static class Entry<K, V> implements BaseEntry<K, V> {
final K k;
V v;
Entry<K, V> next;
Entry(K key, V value, Entry<K, V> next) {
this.k = key;
this.v = value;
this.next = next;
}
@Override
public K getKey() {
return k;
}
@Override
public V getValue() {
return v;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
在插入结点时可以采用头插法,将新元素追加到链表头部。
# 2. 哈希函数实现
可以考虑采用除留余数法,但Java中的HashMap运用了一种更高效的方式,其效果等同于取余。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
2
3
4
5
6
7
8
但这种做法限制了哈希表的长度必须为2的整数次幂。所以在执行构造函数时,若传入的默认数组长度参数不是2的整数次幂,我们需要将他转换成不小于该数的2的整数次幂:
static final int MAXIMUM_CAPACITY = 1 << 30;
public static int roundUpToPowerOf2(int number) {
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
2
3
4
5
6
7
# 3. 哈希表扩容
当装填因子过大时,我们需要给哈希表扩容,以降低冲突的概率。这个过程需要遍历所有元素并重新计算hash函数,效率较低,但可以显著提升查找性能。所以提前分配好合适的容量至关重要。
private void dilatation() {
Entry<K, V>[] newTable = new Entry[arrayLength * 2];
List<Entry<K, V>> list = new ArrayList<>();
for (int i = 0; i < table.length; i++) {
if (table[i] == null)
continue;
// 遍历链表 添加到list
Entry<K, V> entry = table[i];
while (entry != null) {
list.add(entry);
entry = entry.next;
}
}
if (list.size() > 0) {
size = 0;
arrayLength = arrayLength * 2;
table = newTable;
for (Entry<K, V> entry : list) {
// 分离所有的entry
if (entry.next != null) {
entry.next = null;
}
put(entry.getKey(), entry.getValue());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 4. 完整实现
处理完以上几个问题,应该已经没什么难点了,上完整代码:
/**
* 哈希表
*
* @author hukai
*
*/
public class SimpleHashMap<K, V> implements Map<K, V> {
/**
* 默认的初始容量
*/
// DEFAULT_INITIAL_CAPACITY
static final int DEFAULT_INITIAL_CAPACITY = 16;
/**
* 默认的装填因子
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* 最大容量
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* 底层数组
*/
private Entry<K, V>[] table;
/**
* 元素个数
*/
private int size;
/**
* 当前装填因子
*/
private float loadFactor;
/**
* 当前数组长度
*/
private int arrayLength;
private static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
private static int indexFor(int h, int length) {
return h & (length - 1);
}
public SimpleHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public SimpleHashMap(int arrayLength, float loadFactor) {
if (arrayLength < 0) {
throw new IllegalArgumentException("数组异常");
}
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new IllegalArgumentException("因子异常");
}
this.arrayLength = roundUpToPowerOf2(arrayLength);
this.loadFactor = loadFactor;
table = new Entry[this.arrayLength];
}
public static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
@Override
public int size() {
return size;
}
@Override
public boolean isEmpty() {
return size==0;
}
@Override
public V get(K k) {
int index = indexFor(hash(k), table.length);
Entry<K, V> entry = table[index];
if (entry == null) {
throw new NullPointerException();
}
while (entry != null) {
if (k == entry.getKey() || k.equals(entry.getKey())) {
return entry.v;
} else {
entry = entry.next;
}
}
return null;
}
@Override
public V put(K k, V v) {
if (size > loadFactor * arrayLength) {
// 扩容
dilatation();
}
// 计算出下标
int index = indexFor(hash(k), table.length);
Entry<K, V> entry = table[index];
Entry<K, V> newEntry = new Entry<>(k, v, null);
if (entry == null) {
table[index] = newEntry;
size++;// table中有位置被占
} else {
Entry<K, V> t = entry;
if (t.getKey() == k || (t.getKey() != null && t.getKey().equals(k))) {// 相同key
// 对应修改当前value
t.v = v;
} else {
while (t.next != null) {
if (t.next.getKey() == k || (t.next.getKey() != null && t.next.getKey().equals(k))) {// 相同key
// 对应修改当前value
t.next.v = v;
break;
} else {
t = t.next;
}
}
if (t.next == null) {
t.next = newEntry;
}
}
}
return newEntry.getValue();
}
@Override
public void clear() {
Entry<K, V>[] tab;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}
private void dilatation() {
Entry<K, V>[] newTable = new Entry[arrayLength * 2];
List<Entry<K, V>> list = new ArrayList<>();
for (int i = 0; i < table.length; i++) {
if (table[i] == null)
continue;
// 遍历链表 添加到list
Entry<K, V> entry = table[i];
while (entry != null) {
list.add(entry);
entry = entry.next;
}
}
if (list.size() > 0) {
size = 0;
arrayLength = arrayLength * 2;
table = newTable;
for (Entry<K, V> entry : list) {
// 分离所有的entry
if (entry.next != null) {
entry.next = null;
}
put(entry.getKey(), entry.getValue());
}
}
}
static class Entry<K, V> implements BaseEntry<K, V> {
final K k;
V v;
Entry<K, V> next;
Entry(K key, V value, Entry<K, V> next) {
this.k = key;
this.v = value;
this.next = next;
}
@Override
public K getKey() {
return k;
}
@Override
public V getValue() {
return v;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198