 查找算法
查找算法
# 查找概论
# 1. 相关术语
- 査找表(Search Table):由同一类型的数据元素(或记录)构成的集合;
- 关键字(Key):数据元素中某个数据项的值,又称为键值,用它可以标识一个数据元素。
- 主关键字(Primary Key):若某关键字可以唯一地标识一个记录,则称此关键字
- 次关键字 (Seconctary Key):可以识别多个数据元素(或记录)的关键字,我们称为次关键字。也可以理解为是不以唯一标识一个数据元素(或记录)的关键字。
# 2. 查找定义
查找(Searching)就是根据给定的某个值,在査找表中碥定一个其关键字等于给定值的数据元素(或记录)
查找表按照操作方式来分有两大种:静态査找表和动态查找表。
静态査找表(Static SearchTable):只作査找操作的査找表。它的主要操作有:
- 査询某个特定的数据元素是否在査找表中
- 检索某个特定的数据元素和各种属性
动态査找表(Dynamic Search Table):在査找过程中同时插入査找表中不存在的 数据元素,或者从査找表中删除巳经存在的某个败据元素。显然动态查找表的操作就是两个:
- 查找时插入数据元素
- 査找时删除数据元素
下面介绍的查找算法只针对静态查找表,动态查找表将在后续学完二叉树后讲解。
# 顺序查找
# 1. 基本思想
顺序査找又叫线性査找,是最基本的査找技术,它的査找过程是:从表中第一个(或最后一个)记录开始,逐个进行记录的关键字和给定值比较,若某个记录的关键字和给定值相等,则査找成功,找到所査的记录;如果直到最后一个(或第一个)记录,其关键字和给定值比较都不等时,则表中没有所査的记录,査找不成功。
# 2. 代码实现
public int seqSearch(int[] arr, int findVal){
for (int i = 0; i < arr.length; i++) {
if (arr[i] == findVal) {
return i;
}
}
return -1;
}
2
3
4
5
6
7
8
# 3. 思考总结
缺点:是当n 很大时,平均查找长度较大,效率低;
优点:是对表中数据元素的存储没有要求。另外,对于线性链表,只能进行顺序查找。
另外,由于査找槪率的不同,我们完全可以将容易査找到的记录放在前面,而不常用的记录放置在后面,效率就可以有大幅提髙。
# 折半查找
# 1. 基本思想
折半查找又称二分查找(Binary Search)。它的前提是线性表中的记录必须是关键码有序(通常从小到大有序),线性表必须采用顺序存储。
查找过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则查找过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。
这种查找算法每一次比较都使查找范围缩小一半。
# 2. 算法描述
给予一个包含 n个带值元素的有序数组A,查找元素为T:
- 令left=0,right=n-1
- 如果left>right,则搜索以失败告终
- 令 mid(中间值元素)为 (left+right)/2;
- 如果A[mid] < T,令 left为 m + 1 并回到步骤2 ;
- 如果A[mid] < T,令 right为 m - 1 并回到步骤2;
# 3. 代码实现
public static int binarySearch(int[] arr,int findVal,int left,int right){
if (left > right) {
return -1;
}
int mid = (left + right) / 2;
// 说明要查找的数在mid前面
if (arr[mid] > findVal) {
return binarySearch(arr, findVal, left, mid -1);
}else if (arr[mid] < findVal) {
return binarySearch(arr, findVal, mid + 1, right);
}else{
return mid;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# 4. 思考总结
折半搜索每次把搜索区域减少一半,时间复杂度为 O(logn),空间复杂度为O(1)。它显然远远好于顺序査找的O(n)时间复杂度了。
不过由于折半査找的前提条件是需要有序表顺序存储,对于静态査找表,一次排序后不再变化,这样的算法已经比较好了。但对于需要频繁执行插入或删除操作的数据集来说,维护有序的排序会带来不小的工作量,那就不建议使用。
# 插值查找
# 1. 基本思想
插值査找是根据要査找的关键字key与査找表中最大最小记录的关键字比较后的査找方法,其核心就在于插值的计算公式:
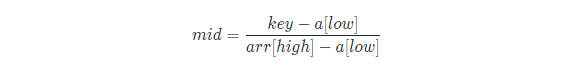
其中,key为待查找的元素,a为查找表,high为最高下标,low为最低下标。
# 2. 算法描述
基于二分查找算法,将查找点的选择改进为自适应选择,可以提高查找效率。当然,差值查找也属于有序查找。
所以,插值查找只是将折半查找的插值计算方式改变了而已。
# 3. 代码实现
public static int binarySearch(int[] arr, int findVal, int low, int high) {
// 注意:findVal < arr[0] || findVal > arr[arr.length-1] 必须需要
// 否则我们得到的 mid 可能越界
if (low > high || findVal < arr[0] || findVal > arr[arr.length - 1]) {
return -1;
}
// 求出mid, 自适应
int mid = low + (high - low) * (findVal - arr[low]) / (arr[high] - arr[low]);
if (arr[mid] > findVal) {
return binarySearch(arr, findVal, low, mid - 1);
} else if (arr[mid] < findVal) {
return binarySearch(arr, findVal, mid + 1, high);
} else {
return mid;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 4. 思考总结
应该说,从时间复杂度来看,它也是O(logn),但对于表长较大,而关键字分布又比较均匀的査找表来说,插值査找算法的平均性能比折半査找要好得多。反之,数组中如果分布非常不均匀,那么插值查找未必是很合适的选择。
# 斐波那契查找
# 1. 基本思想
斐波那契是二分法的改进版,他跟插值查找类似。不同的是它利用了数学领域的黄金分割法则(也就是0.618法则),它避免死板的二分法则,在概率学领域减少了查找次数。
# 2. 算法描述
斐波那契查找原理与前两种相似,仅仅改变了中间结点(mid)的位置,mid不再是中间或插值得到,而是位于黄金分割点附近,即:mid = low + F(k-1) -1 ,(F代表斐波那契数列),如下图所示:

对F(k-1)-1的理解:
- 由斐波那契数列 F[k]=F[k-1]+F[k-2] 的性质,可以得到 (F[k]-1)=(F[k-1]-1)+(F[k-2]-1)+1 。该式说明:只要顺序表的长度为F[k]-1,则可以将该表分成长度为F[k-1]-1和F[k-2]-1的两段,即如上图所示。从而中间位置为mid=low+F(k-1)-1
- 类似的,每一子段也可以用相同的方式分割
- 但顺序表长度n不一定刚好等于F[k]-1,所以需要将原来的顺序表长度n增加至F[k]-1。这里的k值只要能使得F[k]-1恰好大于或等于n即可,由以下代码得到,顺序表长度增加后,新增的位置(从n+1到F[k]-1位置),都赋为n位置的值即可。
//获取到斐波那契分割数值的下标
while(high > f[k] - 1) {
k++;
}
2
3
4
# 3. 代码实现
// 因为后面我们mid=low+F(k-1)-1,需要使用到斐波那契数列,因此我们需要先获取到一个斐波那契数列
// 非递归方法得到一个斐波那契数列
public static int[] fib() {
int[] f = new int[maxSize];
f[0] = 1;
f[1] = 1;
for (int i = 2; i < maxSize; i++) {
f[i] = f[i - 1] + f[i - 2];
}
return f;
}
public static int fibSearch(int[] a, int key) {
int low = 0;
int high = a.length - 1;
int k = 0; //表示斐波那契分割数值的下标
int mid = 0; //存放mid值
int f[] = fib(); //获取到斐波那契数列
//获取到斐波那契分割数值的下标
while(high > f[k] - 1) {
k++;
}
//因为 f[k] 值 可能大于 a 的 长度,因此我们需要使用Arrays类,构造一个新的数组,并指向temp[]
int[] temp = Arrays.copyOf(a, f[k]);
//使用a数组最后的数填充 temp
for(int i = high + 1; i < temp.length; i++) {
temp[i] = a[high];
}
// 只要这个条件满足,就可以找
while (low <= high) {
mid = low + f[k - 1] - 1;
if(key < temp[mid]) {
//我们应该继续向数组的前面查找(左边)
high = mid - 1;
k--;
}else if ( key > temp[mid]) {
// 我们应该继续向数组的后面查找(右边)
low = mid + 1;
k -= 2;
} else { //找到
//需要确定,返回的是哪个下标
if(mid <= high) {
return mid;
} else {
return high;
}
}
}
return -1;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 4. 思考总结
斐波那契査找 的时间复杂也为O(logn),但就平均性能来说,斐波那契査找要优于折半査找。可惜如果是最坏情况,比如这里key=1,那么始终都处于左侧长半区在査找,则査找效率要低于折半査找。
还有比较关键的一点,折半査找是进行加法与除法运算(mid=(loww+high)/2),插值査找进行复杂的四则运算,而斐波那契査找只是最简单加减法运算(mid=low+F[k-1]-1),在海量数据的查找过程中,这种细微的差别可能会影响最终的査找效率。