 遍历二叉树
遍历二叉树
# 二叉树的建立
在讲遍历二叉树之前我们先来看看怎么用Java建立二叉树,前面说过二叉树的存储结构分为顺序存储结构(数组)和二叉链表,下面我们分别用这两种结构建立二叉树。
# 1. 顺序存储结构实现
import java.util.Arrays;
/**
* 二叉树顺序存储实现
* @author hukai
*
*/
public class ArrayBinaryTree<E> {
private static final int DEFAULT_DEEP = 8;
// 使用数组来记录该树的所有节点
private Object[] elementData;
// 保存该树的深度
private int deep;
// 数组长度
private int arraySize;
// 以默认的深度创建二叉树
public ArrayBinaryTree() {
this.deep = DEFAULT_DEEP;
// 二叉树的性质-深度为k的二叉树至多有 2^k -1个结点(k≥1)
this.arraySize = (int) (Math.pow(2, deep) - 1);
elementData = new Object[arraySize];
}
// 以指定深度创建二叉树
public ArrayBinaryTree(int deep) {
if (deep < 0) throw new IllegalArgumentException("树的深度不能小于0");
this.deep = deep;
this.arraySize = (int) Math.pow(2, deep) - 1;
elementData = new Object[arraySize];
}
// 以指定深度、指定根节点创建二叉树
public ArrayBinaryTree(int deep, E data) {
if (deep<=0) throw new IllegalArgumentException("树的深度必须大于0");
if (data == null) throw new NullPointerException("根结点不能为空");
this.deep = deep;
this.arraySize = (int) Math.pow(2, deep) - 1;
elementData = new Object[arraySize];
elementData[0] = data;
}
/**
* 为指定节点添加子节点
* @param parentIndex 双亲结点索引
* @param data 数据
* @param left 是否为左节点
*/
public void add(int parentIndex, E data, boolean left) {
// 添加根结点
if (parentIndex == -1) {
elementData[0] = data;
return;
}
if (elementData[parentIndex] == null) {
throw new RuntimeException(parentIndex + "处节点为空,无法添加子节点");
}
// 获取节点索引
int index = left ? 2 * parentIndex + 1 : 2 * parentIndex + 2;
if (index >= arraySize) {
throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + arraySize);
}
elementData[index] = data;
}
// 判断二叉树是否为空
public boolean empty() {
// 根据根元素判断二叉树是否为空
return elementData[0] == null;
}
// 返回根节点
public E root() {
return elementData(0);
}
// 返回指定节点(非根结点)的父节点
public E parent(int index) {
if (index <= 0) return null;
return elementData((index - 1) / 2);
}
// 返回指定节点(非叶子)的左子节点,当左子节点不存在时返回null
public E leftChild(int index) {
if (2 * index + 1 >= arraySize) {
throw new RuntimeException("该节点为叶子节点,无子节点");
}
return elementData(index * 2 + 1);
}
// 返回指定节点(非叶子)的右子节点,当右子节点不存在时返回null
public E rightChild(int index) {
if (2 * index + 1 >= arraySize) {
throw new RuntimeException("该节点为叶子节点,无子节点");
}
return elementData(index * 2 + 2);
}
// 返回指定节点的位置
public int position(E data) {
// 该循环实际上就是按广度遍历来搜索每个节点
for (int i = 0; i < arraySize; i++) {
if (elementData[i].equals(data)) {
return i;
}
}
return -1;
}
/**
* 返回此列表中指定位置的元素
*/
@SuppressWarnings("unchecked")
private E elementData(int index) {
return (E) elementData[index];
}
@Override
public String toString() {
return Arrays.toString(elementData);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
# 2. 二叉链表的实现
/**
* 二叉链表的实现
*
* @author hukai
*
*/
public class LinkedBinaryTree<E> {
// 根结点
private TreeNode<E> root;
// 以默认的构造器创建二叉树
public LinkedBinaryTree() {
this.root = new TreeNode<E>();
}
// 以指定根元素创建二叉树
public LinkedBinaryTree(E element) {
this.root = new TreeNode<E>(element);
}
/**
* 为指定节点添加子节点
*
* @param parent
* 需要添加子节点的父节点
* @param data
* 新子节点的数据
* @param isLeft
* 是否为左节点
* @return
*/
public TreeNode<E> addNode(TreeNode<E> parent, E data, boolean isLeft) {
if (parent == null) {
throw new RuntimeException("父节点为null, 无法添加子节点");
}
if (isLeft && parent.leftChild != null) {
throw new RuntimeException("父节点已有左子节点,无法添加左子节点");
}
if (!isLeft && parent.rightChild != null) {
throw new RuntimeException("节点已有右子节点,无法添加右子节点");
}
TreeNode<E> newNode = new TreeNode<E>(data);
if (isLeft) {
// 让父节点的left引用指向新节点
parent.leftChild = newNode;
} else {
// 让父节点的left引用指向新节点
parent.rightChild = newNode;
}
return newNode;
}
// 判断二叉树是否为空
public boolean empty() {
// 根据元素判断二叉树是否为空
return root.element == null;
}
// 返回根节点
public TreeNode<E> root() {
if (empty()) {
throw new RuntimeException("树为空,无法访问根节点");
}
return root;
}
// 返回该二叉树的深度
public int deep() {
// 获取该树的深度
return deep(root);
}
// 这是一个递归方法:每一棵子树的深度为其所有子树的最大深度 + 1
private int deep(TreeNode<E> node) {
if (node == null)
return 0;
// 没有子树
if (node.leftChild == null && node.rightChild == null) {
return 1;
} else {
int leftDeep = deep(node.leftChild);
int rightDeep = deep(node.rightChild);
int max = Math.max(leftDeep, rightDeep);
// 返回其左右子树中较大的深度 + 1
return max + 1;
}
}
/**
* 内部结点类
*
* @author hukai
*
*/
public static class TreeNode<E> {
// 数据元素
E element;
// 左孩子
TreeNode<E> leftChild;
// 右孩子
TreeNode<E> rightChild;
public TreeNode() {
}
public TreeNode(E element) {
this.element = element;
}
public TreeNode(E element, TreeNode<E> left, TreeNode<E> right) {
this.element = element;
this.leftChild = left;
this.rightChild = right;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
上次还提到过三叉链表,其实对比二叉链表只是内部结点类增加了一个指向父节点的指针,在此不做赘述。
# 二叉树的遍历
# 1. 前序遍历
规则是若二叉树为空,则空操作返回,否则先访问根结点,然后前序遍历左子树,再前序遍历右子树。
按照前序遍历地方式,遍历如下二叉树,则访问顺序为:A、B、D、H、I、E、J、C、F、G。
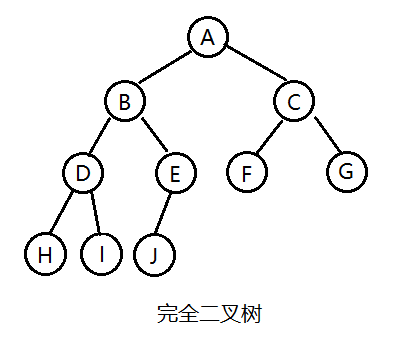
以上面实现的二叉链表为例,前序遍历算法如下:
/**
* 前序遍历
* @param node
*/
public void PreOrderTraverse(TreeNode<E> node){
if (node == null) return;
// 先访问根节点
System.out.println(node.element);
// 前序遍历左子树
PreOrderTraverse(node.leftChild);
// 前序遍历右子树
PreOrderTraverse(node.rightChild);
}
2
3
4
5
6
7
8
9
10
11
12
13
# 2. 中序遍历
规则是若树为空,则空操作返回,否则从根结点开始(注意并不是先访问根结点),中序遍历根结点的左子树,然后是访问根结点,最后中序遍历右子树。
按照中序遍历地方式,遍历如下二叉树,则访问顺序为:H、D、I、B、J、E、A、F、C、G。
中序遍历算法和前序遍历类似:
/**
* 中序遍历
* @param node
*/
public void inOrderTraverse(TreeNode<E> node){
if (node == null) return;
// 中序遍历左子树
inOrderTraverse(node.leftChild);
// 访问根节点
System.out.println(node.element);
// 中序遍历右子树
inOrderTraverse(node.rightChild);
}
2
3
4
5
6
7
8
9
10
11
12
13
# 3. 后序遍历
规则是若树为空,则空操作返回,否则从左到右先叶子后结点的方式遍历访问左右子树,最后是访问根结点。
按照后序遍历地方式,遍历如下二叉树,则访问顺序为:H、D、I、B、J、E、A、F、C、G。
后序遍历算法:
/**
* 后序遍历
* @param node
*/
public void postOrderTraverse(TreeNode<E> node){
if (node == null) return;
// 后序遍历左子树
postOrderTraverse(node.leftChild);
// 后序遍历右子树
postOrderTraverse(node.rightChild);
// 后访问根节点
System.out.println(node.element);
}
2
3
4
5
6
7
8
9
10
11
12
13
# 4. 层序遍历
规则是若树为空,则空操作返回,否则从树的第一层,也就是根结点开始访问,从上而下逐层遍历,在同一层中,按从左到右的顺序对结点逐个访问。
按照层序遍历地方式,遍历如下二叉树,则访问顺序为:A、B、C、D、E、F、G、H、I、J。
不难发现,在顺序存储结构实现的二叉树中,层序遍历实际上就是遍历数组,在此不做赘述。
# 非递归方式实现二叉树遍历
上面实现二叉树的三种遍历方式(前序、中序、后序)都采用了递归的方式,能否不采用递归方式实现这三种遍历呢?答案是肯定的,我们可以利用栈来实现。
# 1. 非递归方式实现前序遍历
具体步骤:
- 首先创建一个新的栈,记为stack;
- 将头结点head压入stack中;
- 每次从stack中弹出栈顶节点,记为cur,然后打印cur值;
- 如果cur右孩子不为空,则将右孩子压入栈中;如果cur的左孩子不为空,将其压入stack中;
- 重复步骤3,4,直到stack为空
过程模拟:
代码实现:
public void preOrderTraverse(ThreadedNode<T> node){
if (node == null) return;
// 将头结点head压入stack中
Stack<ThreadedNode<T>> stack = new Stack<ThreadedNode<T>>();
stack.push(node);
// 从stack中弹出栈顶节点,记为cur,然后打印cur值
do {
ThreadedNode<T> curNode = stack.pop();
System.out.print(curNode.getData() + " ");
// 如果cur右孩子不为空,则将右孩子压入栈中
if (curNode.getRightNode() != null) {
stack.push(curNode.getRightNode());
}
// 如果cur的左孩子不为空,将其压入stack中
if (curNode.getLeftNode() != null) {
stack.push(curNode.getLeftNode());
}
} while (!stack.isEmpty());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 2. 非递归方式实现中序遍历
具体步骤:
- 创建一个新栈,记为stack,申请一个变量cur,初始时令cur为头节点;
- 先把cur节点压入栈中,对以cur节点为头的整棵子树来说,依次把整棵树的左子树压入栈中,即不断令cur=cur.left,然后重复步骤2;
- 不断重复步骤2,直到发现cur为空,此时从stack中弹出一个节点记为temp,打印temp的值,并让cur = temp.right,然后继续重复步骤2;
- 当stack为空并且cur为空时结束;
过程模拟:
public void inOrderTraverse(ThreadedNode<T> node){
if (node == null) return;
Stack<ThreadedNode<T>> stack = new Stack<ThreadedNode<T>>();
// 申请一个变量cur,初始时令cur为头节点
ThreadedNode<T> curNode = node;
do {
// 先把cur节点压入栈中,对以cur节点为头的整棵子树来说,依次把整棵树的左子树压入栈中
while (curNode!= null) {
stack.push(curNode);
curNode = curNode.getLeftNode();
}
// 此时cur为空,从stack中弹出一个节点记为temp,打印node的值,并让cur = temp.right
ThreadedNode<T> tempNode = stack.pop();
System.out.print(tempNode.getData() + " ");
curNode = tempNode.getRightNode();
} while (!stack.isEmpty() || curNode != null);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 3. 非递归方式实现后序遍历
具体步骤:
- 申请两个栈stack1,stack2,然后将头结点压入stack1中;
- 从stack1中弹出的节点记为cur,然后先把cur的左孩子压入stack1中,再把cur的右孩子压入stack1中;
- 在整个过程中,每一个从stack1中弹出的节点都放在第二个栈stack2中;
- 不断重复步骤2和步骤3,直到stack1为空,过程停止;
- 从stack2中依次弹出节点并打印,打印的顺序就是后序遍历的顺序;
过程模拟:
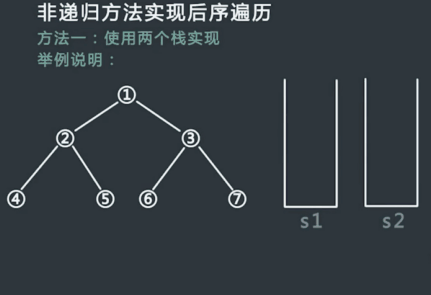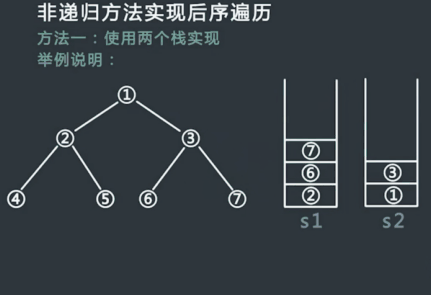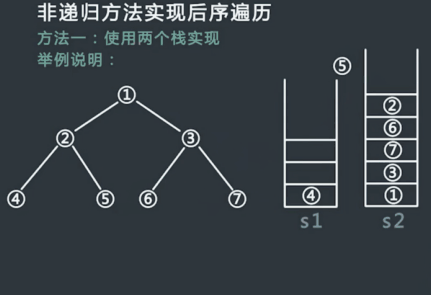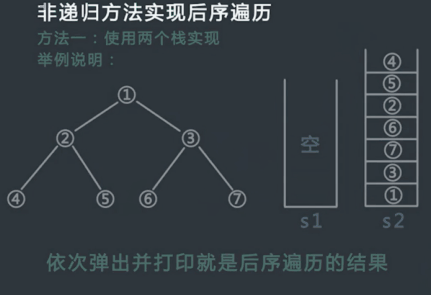
代码实现:
public void postOrderTraverse(ThreadedNode<T> node){
if (node == null) return;
// 创建两个栈stack1,stack2
Stack<ThreadedNode<T>> stack1 = new Stack<ThreadedNode<T>>();
Stack<ThreadedNode<T>> stack2 = new Stack<ThreadedNode<T>>();
// 将头结点压入stack1中
stack1.push(node);
do {
// 从stack1中弹出的节点记为cur,然后先把cur的左孩子压入stack1中,再把cur的右孩子压入stack1中;
ThreadedNode<T> curNode = stack1.pop();
if (curNode.getLeftNode() != null) {
stack1.push(curNode.getLeftNode());
}
if (curNode.getRightNode() != null) {
stack1.push(curNode.getRightNode());
}
// 从stack1中弹出的节点都放在第二个栈stack2中
stack2.push(curNode);
} while (!stack1.isEmpty());
// 从stack2中依次弹出节点并打印,打印的顺序就是后序遍历的顺序
while(!stack2.isEmpty()){
ThreadedNode<T> tempNode = stack2.pop();
System.out.print(tempNode.getData() + " ");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
其实,使用一个栈也能实现非递归后序遍历,可以思考一下,再次不详述。