 赫夫曼树及其应用
赫夫曼树及其应用
# 赫夫曼树定义与原理
# 1. 相关名词介绍
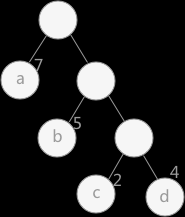
路径:在一棵树中,一个结点到另一个结点之间的通路,称为路径。下图中,从根结点到结点a之间的通路就是一条路径。
路径长度:从树中一个结点到另一个结点之间的分支构成两个结点之间的路径,路径上的分支数目称做路径长度 。例如在一棵树中,规定根结点所在层数为1层,那么从根结点到第 i 层结点的路径长度为 i - 1 。下图中从根结点到结点 c 的路径长度为 3。
树的路径长度:树的路径长度就是从树根到毎一结点的路径长度之和。如下图树的路径长度为:1+1+2+2+3+3=12
结点的权:给每一个结点赋予一个新的数值,被称为这个结点的权。例如,图 1 中结点 a 的权为 7,结点 b 的权为 5。
结点的带权路径长度:指的是从根结点到该结点之间的路径长度与该结点的权的乘积。例如,图 1 中结点 b 的带权路径长度为 2 * 5 = 10 。
树的带权路径长度:树中所有叶子结点的带权路径长度之和。通常记作 WPL 。下图所示这棵树的带权路径长度为:WPL = 7 * 1 + 5 * 2 + 2 * 3 + 4 * 3 = 35
# 2. 什么是赫夫曼树
当用 n 个结点(都做叶子结点且都有各自的权值)试图构建一棵树时,如果构建的这棵树的带权路径长度最小,称这棵树为赫夫曼树。
很多书中也称为最优二叉树,或者叫哈夫曼树。其实都是一个概念。
# 3. 怎么构建赫夫曼树
在构建赫夫曼树时,要使树的带权路径长度最小,只需要遵循一个原则,那就是:权重越大的结点离树根越近。在上图中,因为结点a的权值最大,所以理应直接作为根结点的孩子结点。
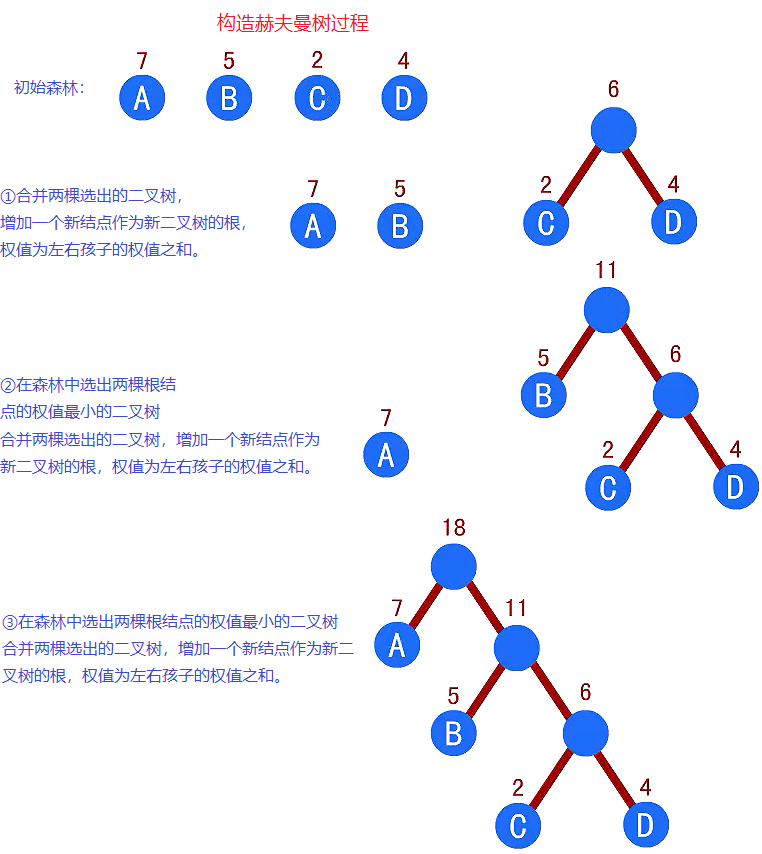
赫夫曼树的构造(赫夫曼算法):
- 根据给定的n个权值{w1,w2,…,wn}构成二叉树集合F={T1,T2,…,Tn},其中每棵二叉树Ti中只有一个带权为wi的根结点,其左右子树为空.
- 在F中选取两棵根结点权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为左右子树根结点的权值之和.
- 在F中删除这两棵树,同时将新的二叉树加入F中.
- 重复2、3,直到F只含有一棵树为止.(得到赫夫曼树);
# 4. 关于赫夫曼树的注意点
- 满二叉树不一定是赫夫曼树
- 赫夫曼树中权越大的叶子离根越近 (很好理解,WPL最小的二叉树)
- 具有相同带权结点的赫夫曼树不唯一
- 赫夫曼树的结点的度数为 0 或 2, 没有度为 1 的结点。
- 包含 n 个叶子结点的赫夫曼树中共有 2n – 1 个结点。
- 包含 n 棵树的森林要经过 n–1 次合并才能形成赫夫曼树,共产生 n–1 个新结点
# Java实现赫夫曼树
# 1. 结点结构实现
赫夫曼树的结点结构与普通的二叉树类似,不过需要增加一个成员变量,即结点的权值。同时,因为在构建赫夫曼树时需要对根据权值对结点进行排序,所以还需要实现Comparable接口。代码如下:
/**
* 赫夫曼树结点结构
* @author hukai
*
*/
public class HuffmanNode<T> implements Comparable<HuffmanNode<T>>{
// 数据
private T data;
// 节点权重
private int weight;
private HuffmanNode<T> leftNode,rightNode;
public HuffmanNode() {
}
public HuffmanNode(T data, int weight) {
super();
this.data = data;
this.weight = weight;
}
@Override
public int compareTo(HuffmanNode<T> o) {
return o.weight - this.weight;
}
// getter setter
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 2. 构建赫夫曼树的代码实现
构建赫夫曼树时,需要每次根据各个结点的权值,筛选出其中值最小的两个结点,然后构建二叉树。
import java.util.Collections;
import java.util.List;
/**
* 赫夫曼树
* @author hukai
*
* @param <T>
*/
public class HuffmanTree<T> {
/**
* 创建赫夫曼树
* @param datas
* @return
*/
public static <T> HuffmanNode<T> createHuffmanTree(List<HuffmanNode<T>> nodes) {
while (nodes.size() > 1) {
// 根据权值对集合进行排序
Collections.sort(nodes);
// 取出权值最小的两个二叉树
HuffmanNode<T> leftNode = nodes.get(nodes.size() - 1);
HuffmanNode<T> rightNode = nodes.get(nodes.size() - 2);
//创建一颗新的二叉树
HuffmanNode<T> root = new HuffmanNode<>(null,leftNode.getWeight()+rightNode.getWeight());
root.setLeftNode(leftNode);
root.setRightNode(rightNode);
//把取出来的两个二叉树移除
nodes.remove(leftNode);
nodes.remove(rightNode);
nodes.add(root);
}
return nodes.get(0);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 赫夫曼编码
赫夫曼研究这种最优树的目的是为了解决当年远距离通信(主要是电报)的数据传送的最优化问题。
我们以网络传输一段文字内容为“BADCADFEED”为例。如果用二进制的数字(0和1)来表示:
| 字母 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 二进制字符 | 000 | 001 | 010 | 011 | 100 | 101 |
真正传输的数据就是编码后的“001 000 011 010 000 011 101 100 100 001”。为了看起清楚,我在每个字母的二进制串之间添加了空格。实际上,如果传输一篇很长的文章,这个二进制串就非常大,同时不同字母的出现频率是不相同的。假设这六个字母的频率为:
| 字母 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 出现频率 | 27 | 8 | 15 | 15 | 30 | 5 |
下图中左边为构造赫夫曼树的过程的权值显示。右边为将权值左分支改为0, 右分支改为1后的赫夫曼树:
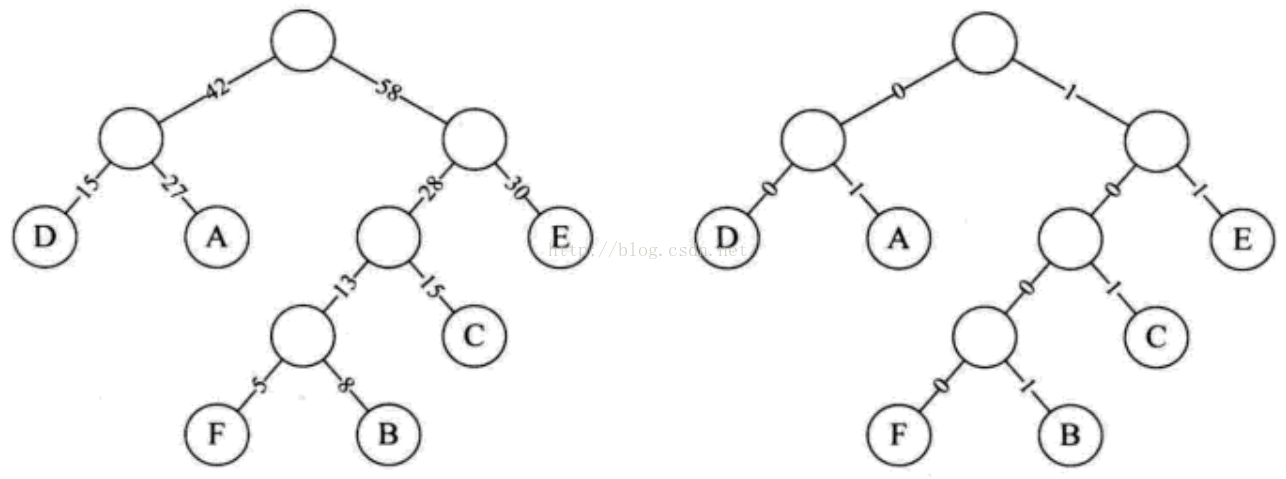
此时,我们对这六个字母用其从树根到叶子所经过路径的0或1来编码,得到下表:
| 字母 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|
| 二进制字符 | 01 | 1001 | 101 | 00 | 11 | 1000 |
我们将文字内容为“BADCADFEED*再次编码,对比可以看到结果串变小了:
- 原编码二进制串:001000011010000011101100100011 (共 30 个字符)
- 新编码二进制串:1001010010101001000111100 (共 25 个字符)
对比结果节约了大约17%数据空间。随着字符的増加和多字符权重的不同,这种压缩会更加显出其优势。
当我们接收到1001010010101001000111100这样压缩过的新编码时,我们应该如何把它解码出来呢?
编码中非0即1,长短不等的话其实是很容易混淆的,所以若要设计长短不等的编码,则必须是任一字符的编码都不是另一个字符的编码的前缀,这种编码称做前缀编码。
回到上面根据郝夫曼树生成的编码,我们发现这种编码就不存在容易混淆的编码。可仅仅是这样不足以让我们去方便地解码的,因此在解码时,还是要用到赫夫曼 树,即发送方和接收方必须要约定好同样的赫夫曼编码规则。
当我们接收到1001010Q10101001000111100时,由约定好的赫夫曼树可知,1001得到第一个字母是B,接下来01意味着第二个字符是A,如图所示:
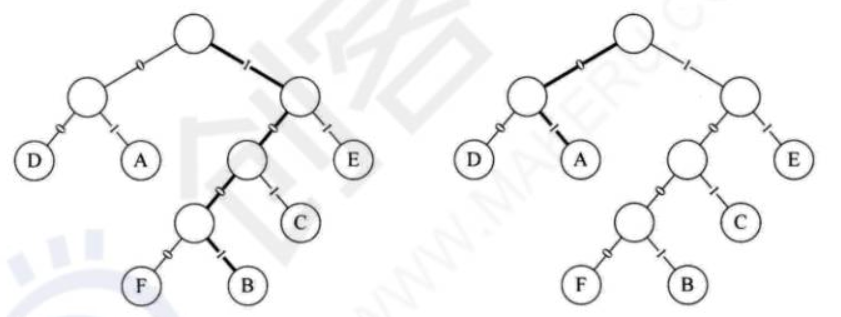
—般地,设需要编码的字符集为{d1,d2,...,dn},各个字符在电文中出现的次数或频率集合为{w1,w2,...,wn},以d1,d2,...,dn作为叶子结点,以w1,w2,...,wn作为相应叶子结点的权值来构造一棵赫夫曼树。规定赫夫曼树的左分支代表0,右分支代表1,则从根结点到叶子结点所经过的路径分支组成的0和1的序列便为该结点对应字符的编码,这就是赫夫曼编码。