 栈
栈
# 栈的定义
栈是限定仅在表尾进行插入和删除操作的线性表。
我们把允许插入和删除的一端称为栈顶,另一端称为栈底,不含任何数据元素的栈称为空栈。
栈又称为后进先出(Last In First Out)的线性表,简称LIFO结构。
既然是线性表,栈元素就具有线性关系,即前驱后继关系。只不过它是一只特殊的线性表,它的特殊之处就在于限制了这个线性表的插入和删除位置,它始终只在栈顶进行。这也使得栈底是固定的,最先进栈的只能在栈底。
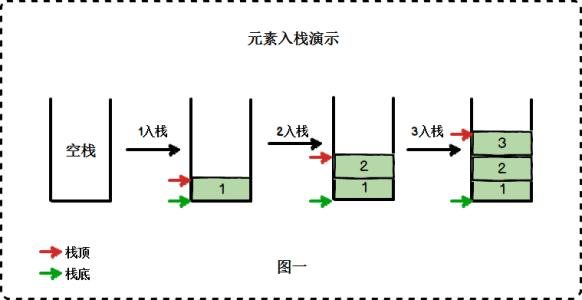
栈的插入操作,叫做进栈,也叫压栈、入栈。
栈的删除操作,叫做出栈,也有的叫做弹栈。
# 栈的抽象数据类型
对于栈来说,理论上线性表的操作特性它都具备,但由于它的特殊性,在操作上会有些变化,比如插入和删除操作,我们改名为push和pop,英文直译就是压和弹,更容易理解。
/**
* 栈的抽象数据类型
* @author hukai
*/
public interface Stack<E> {
/**
* 清空栈
*/
void clear();
/**
* 获取栈的元素个数
*/
int size();
/**
* 判断是否为空栈
*/
boolean isEmpty();
/**
* 查看栈顶元素
*/
E peek();
/**
* 进栈
*/
E push(E item);
/**
* 出栈
*/
E pop();
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 栈的顺序存储结构实现
要实现顺序存储结构,必然离不开数组。既然是数组,必然需要扩容,将索引为0一端作为栈底。我们可以模仿ArrayList实现栈的顺序存储结构。
import java.util.Arrays;
import java.util.EmptyStackException;
public class SequenceStack<E> implements Stack<E>{
/**
* 默认初始容量大小
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* 空数组(用于空实例)。
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
// 用于默认大小空实例的共享空数组实例。
// 我们把它从EMPTY_ELEMENTDATA数组中区分出来,以知道在添加第一个元素时容量需要增加多少。
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* 保存数据的数组
*/
transient Object[] elementData;
/**
* 要分配的最大数组大小
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
/**
* 所包含的元素个数
*/
private int size;
/**
* 带初始容量参数的构造函数。(用户自己指定容量)
*/
public SequenceStack(int initialCapacity) {
if (initialCapacity > 0) {
// 创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
// 创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("初始容量数据不合法:" + initialCapacity);
}
}
/**
* 默认构造函数,DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10,也就是说初始其实是空数组
* 当添加第一个元素的时候数组容量才变成10
*/
public SequenceStack() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* 保证内部数组容量
*
* @param minCapacity
*/
private void ensureCapacityInternal(int minCapacity) {
// 得到最小扩容量
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
// 判断是否需要扩容
ensureExplicitCapacity(minCapacity);
}
/**
* 判断是否需要扩容,如果需要,调用grow方法进行扩容
*
* @param minCapacity
*/
private void ensureExplicitCapacity(int minCapacity) {
if (minCapacity - elementData.length > 0) {
// 调用grow方法进行扩容,调用此方法代表已经开始扩容了
grow(minCapacity);
}
}
/**
* 扩容的核心方法。
*/
private void grow(int minCapacity) {
// oldCapacity为旧容量,newCapacity为新容量
int oldCapacity = elementData.length;
// 将oldCapacity 右移一位,其效果相当于oldCapacity /2,
// 我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 再检查新容量是否超出了定义的最大容量
// 如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为
// MAX_ARRAY_SIZE。
if (newCapacity - MAX_ARRAY_SIZE > 0) {
newCapacity = (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE;
}
// 调用copyOf方法创建新数组,并将原数组元素拷贝过去
elementData = Arrays.copyOf(elementData, newCapacity);
}
@Override
public void clear() {
for (int i = 0; i < size; i++) {
elementData[i] = null;
}
size = 0;
}
/**
* 返回此列表中的元素数
*/
@Override
public int size() { return size; }
/**
* 返回此列表是否为空
*/
@Override
public boolean isEmpty() { return size == 0; }
/**
* 返回栈顶元素,不移除栈顶
*/
@Override
public E peek() {
if (size == 0) throw new EmptyStackException();
return elementData(size - 1);
}
/**
* 将元素追加到列表的末尾,即为入栈
*/
@Override
public E push(E item) {
ensureCapacityInternal(size + 1);
// 添加元素的实质就相当于为数组赋值
elementData[size++] = item;
return item;
}
/**
* 出栈
*/
@Override
public E pop() {
if (size == 0) throw new EmptyStackException();
final E item = elementData(size - 1);
elementData[size--] = null;
return item;
}
/**
* 返回此列表中指定位置的元素
*/
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
@Override
public String toString() {
if (size <=0) return "[]";
StringBuilder sb = new StringBuilder();
sb.append("[");
for (int i = 0; i < size; i++) {
sb.append(elementData(i));
if (i< size - 1) sb.append(",");
}
sb.append("]");
return sb.toString();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
# 栈的链式存储结构实现
栈的链式存储结构,简称为链栈。
由于栈只是栈顶做插入和删除操作。我们构建一条单链表即可,每次插入数据都在链表的顶端进行:
/**
* 栈的链式存储结构实现
* @author hukai
*/
public class LinkedStack<E> implements Stack<E> {
/**
* 所包含的节点个数
*/
private int size = 0;
/**
* 尾节点
*/
private Node<E> top;
@Override
public void clear() {
for (Node<E> x = top; x != null;) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x = next;
}
top = null;
size = 0;
}
/**
* 返回此列表中的元素数
*/
@Override
public int size() {
return size;
}
/**
* 返回此列表是否为空
*/
@Override
public boolean isEmpty() {
return size == 0;
}
/**
* 查看栈顶元素
*/
@Override
public E peek() {
if (size == 0) throw new EmptyStackException();
return top.item;
}
/**
* 入栈
*/
@Override
public E push(E item) {
final Node<E> t = top;
final Node<E> newNode = new Node<E>(item, t);
top = newNode;
size++;
return item;
}
/**
* 出栈
*/
@Override
public E pop() {
if (size == 0) throw new EmptyStackException();
final Node<E> f = top;
top = top.next;
size--;
return f.item;
}
/**
* Node内部类
*/
private static class Node<E> {
E item;
Node<E> next;
Node(E element, Node<E> next) {
this.item = element;
this.next = next;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
总结:链栈和顺序栈的时间复杂度都为O(1),但是由于链栈需要一个指向下一个节点的指针域所以额外占的空间会大一些,但同时它也由栈的长度不限的优点。综合起来,如果所栈元素的数目会在使用过程中发生较大的改变,我们一般使用链栈,而倘如我们栈的元素数目是固定不变的,则最好采用顺序栈的方式来存储。
# 栈的应用-四则运算表达式求值
# 1. 中缀表达式
中缀表达式就是常见的运算表达式,如(3+4)×5-6。
对于人们来说,也是最直观的一种求值方式,先算括号里的,然后算乘除,最后算加减,但是,计算机处理中缀表达式却并不方便,因为没有一种简单的数据结构可以方便从一个表达式中间抽出一部分算完结果,再放进去,然后继续后面的计算(链表也许可以,但是,代价也是不菲)。因此,在计算结果时,往往会将中缀表达式转成其它表达式来操作。
在介绍前缀,后缀表达式之前,我想先通过我们最熟悉的中缀表达式画出一棵语法树来直观认识前后缀表达式。以 A+B*(C-D)-E*F 为例:
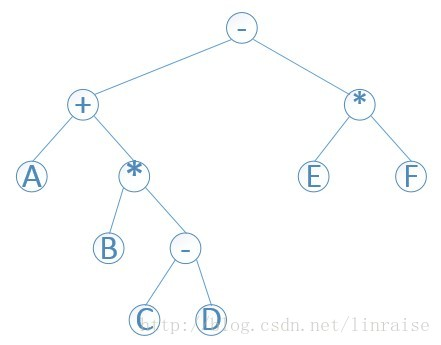
中缀表达式得名于它是由相应的语法树的中序遍历的结果得到的。
# 2. 前缀表达式(波兰式)
前缀表达式又叫做波兰式。同样的道理,表达式的前缀表达式是由相应的语法树的前序遍历的结果得到的。
如上图的前缀表达式为- + A * B - C D * E F。
由前缀表达式求出结果的思路为:
从右至左扫描表达式,遇到数字时,将数字压入堆栈,遇到运算符时,弹出栈顶的两个数,用运算符对它们做相应的计算(栈顶元素 和 次顶元素),并将结果入栈;重复上述过程直到表达式最左端,最后运算得出的值即为表达式的结果。
例如: (3+4)×5-6 对应的前缀表达式就是 - × + 3 4 5 6 , 针对前缀表达式求值步骤如下:
- 从右至左扫描,将6、5、4、3压入堆栈
- 遇到+运算符,因此弹出3和4(3为栈顶元素,4为次顶元素),计算出3+4的值,得7,再将7入栈
- 接下来是×运算符,因此弹出7和5,计算出7×5=35,将35入栈
- 最后是-运算符,计算出35-6的值,即29,由此得出最终结果
# 3. 后缀表达式(逆波兰式)
后缀表达式又叫做逆波兰式。它是由相应的语法树的后序遍历的结果得到的。与前缀表达式相似,只是运算符位于操作数之后,如上图的后缀表达式为: A B C D - * + E F * -
由逆波兰表达式求出结果的思路为:
从左至右扫描表达式,遇到数字时,将数字压入堆栈,遇到运算符时,弹出栈顶的两个数,用运算符对它们做相应的计算(次顶元素和栈顶元素),并将结果入栈;重复上述过程直到表达式最右端,最后运算得出的值即为表达式的结果。
例如: (3+4)×5-6 对应的后缀表达式就是 3 4 + 5 × 6 - , 针对后缀表达式求值步骤如下:
- 从左至右扫描,将3和4压入堆栈
- 遇到+运算符,因此弹出4和3(4为栈顶元素,3为次顶元素),计算出3+4的值,得7,再将7入栈;
- 将5入栈
- 接下来是×运算符,因此弹出5和7,计算出7×5=35,将35入栈
- 将6入栈
- 最后是-运算符,计算出35-6的值,即29,由此得出最终结果
# 4. 中缀表达式转后缀表达式
后缀表达式适合计算式进行运算,但是人却不太容易写出来,尤其是表达式很长的情况下,因此在开发中,我们需要将中缀表达式转成后缀表达式。
具体步骤为: 从左到右遍历中缀表达式的每个数字和符号,若是数字就输出,即成为后缀表达式的一部分;若是符号,则判断其与栈顶符号的优先级,是右括号或优先级低于栈顶符号(乘除优先加减)则栈顶元素依次出栈并输出,并将当前符号进栈,一直到最终输出后缀表达式为止。
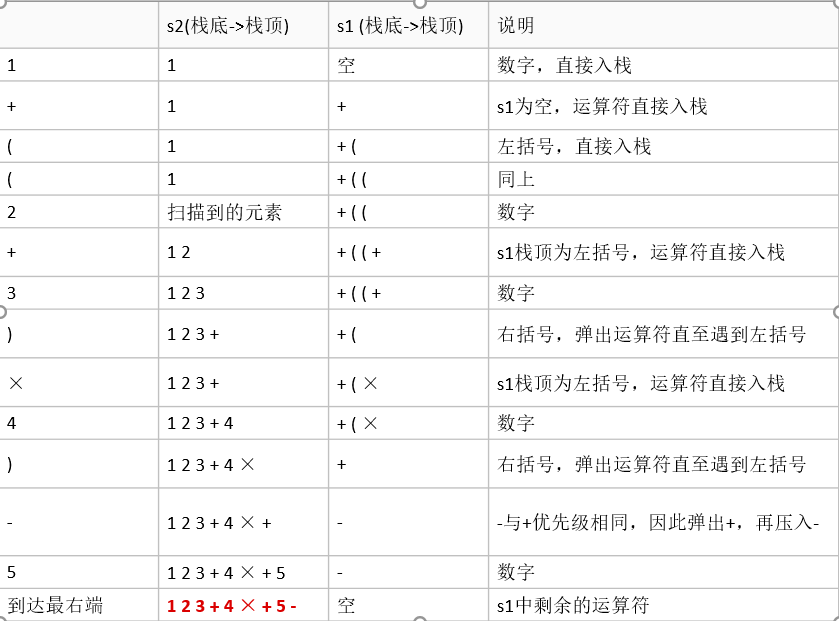
举例说明:将中缀表达 式“1+((2+3)×4)-5”转换为后缀表达式的过程如下:
# 栈的应用-递归
# 1. 递归的定义
递归:在一个方法(函数)的内部调用该方法(函数)本身的编程方式。
如下图所示:
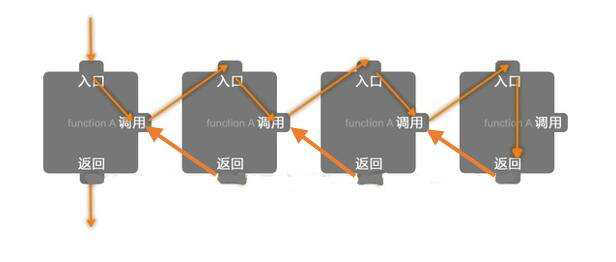
写递归程序最怕的就是陷入永不结束的无穷递归之中,所以没个递归定义必须至少有一个条件,满足时递归不再进行,即不再引用自身而是返回值退出。
# 2. 递归实现斐波那契数列
斐波那契数列数列从第3项开始,每一项都等于前两项之和。比如: 1,1,2,3,5,8,13,21,34.......
关于这个数列的介绍网上有很多,在此不做赘述,下面我们用递归实现斐波那契数列:
public static int fibonacci(int i){
if (i<=2) {
return 1;
}
return fibonacci(i-1)+fibonacci(i-2);
}
2
3
4
5
6
# 3. 递归和栈的关系
说了那么多,递归和栈有啥关系?这得从计算机内部说起。
递归过程的退回顺序是它前行顺序的逆序。在退回过程中,可能要执行某些动作,包括恢复在前行过程中存储起来的某些数据。
这种存储某些数据,并在后面有以存储的逆序恢复这些数据,以提供之后使用的需求,显然很符合栈这样的数据结构。因此,编译器使用栈实现递归就没什么好惊讶的了。
# 递归-八皇后问题(回溯算法)
# 1. 八皇后问题介绍
八皇后问题,是一个古老而著名的问题,是回溯算法的典型案例。该问题是国际西洋棋棋手马克斯·贝瑟尔于1848年提出:在8×8格的国际象棋上摆放八个皇后,使其不能互相攻击,即:任意两个皇后都不能处于同一行、同一列或同一斜线上,问有多少种摆法?
