 线索二叉树
线索二叉树
# 线索二叉树原理
我们在有n个结点的二叉链表中,每个结点有指向左右2个孩子的指针域,所以有2n个指针域,而n个结点的二叉树一共有n-1条分支线,也就是说,其实存在2n-(n-1) = n+1 个空指针域。空间十分浪费。
如下图所示一棵二叉树一共有10个结点,空指针有11个。
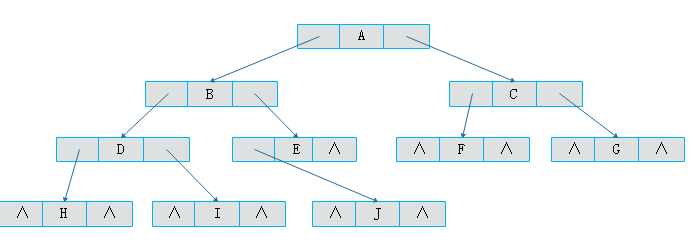
另一方面,我们在做遍历时,比如对上图做中序遍历,结果为H、D、I、B、J、E、A、F、C、G。可以得知A的前驱结点为E,后继结点为F。但是,这种关系的获得是建立在完成遍历后得到的,那么可不可以在建立二叉树时就记录下前驱后继的关系呢?那么在后续寻找前驱结点和后继结点时将大大提升效率。
综合刚才两个角度的分析后,我们可以考虑利用那些空地址,存放指向结点在某种遍历次序下的前驱和后继结点的地址。我们把这种指向前驱和后继的指针称为线索,加上线索的二叉链表称为线索链表,相应的二叉树就称为线索二叉树。
# 线索化
为了存放指向结点在某种遍历次序下的前驱和后继结点的地址,我们定义如下规则:
- 若结点的左子树为空,则该结点的左孩子指针指向其前驱结点
- 若结点的右子树为空,则该结点的右孩子指针指向其后继结点
这种指向前驱和后继的指针称为线索。将一棵普通二叉树以某种次序遍历,并添加线索的过程称为线索化。
按照规则将上图所示二叉树中序线索化后如图所示:
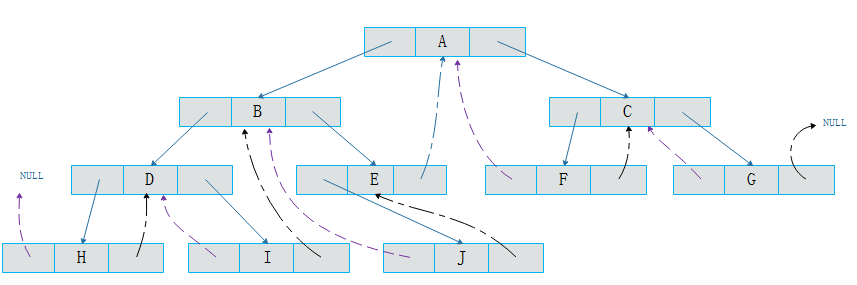
图中黑色点画线为指向后继的线索,紫色虚线为指向前驱的线索。
可以看出通过线索化,既解决了空间浪费问题,又解决了前驱后继的记录问题。但是新问题又产生了,我们如何区分一个结点的leftChild指针是指向左孩子还是前驱结点呢?例如:对于上图所示的结点E,如何区分其leftChild的指向的结点J是其左孩子还是前驱结点呢?
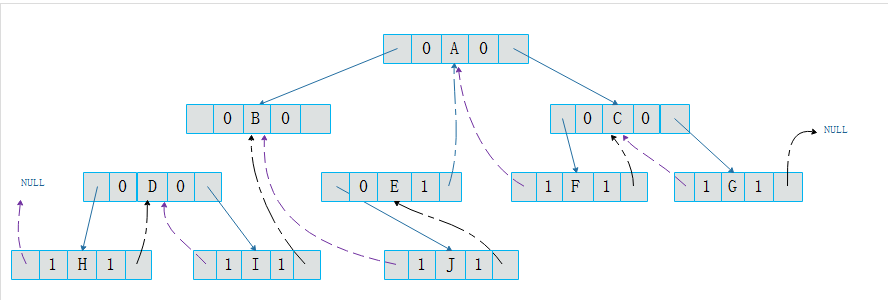
为了解决这一问题,现需要添加标志位leftFlag,rightFlag。并定义规则如下:
- leftFlag为0时,指向左孩子,为1时指向前驱
- rightFlag为0时,指向右孩子,为1时指向后继
添加leftFlag和rightFlag属性后的结点结构如下:

将上图线索二叉树转变为如下图所示的二叉树:
# 线索二叉树Java实现
# 1. 线索二叉树结构实现
由此二叉树的线索存储结构定义代码如下:
/**
* 线索二叉树结点结构
* @author hukai
*
*/
public class ThreadedNode<T> {
private ThreadedNode<T> leftNode, rightNode;
//左孩子是否为线索,右孩子是否为线索
private boolean leftThreadFlag, rightThreadFlag;
private T data;
public ThreadedNode() {
this.leftThreadFlag = false;
this.rightThreadFlag = false;
}
public ThreadedNode(T data){
this.data = data;
this.leftThreadFlag = false;
this.rightThreadFlag = false;
}
// getter setter...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 2. 线索二叉树实现
线索化的实质就是将二叉链表中的空指针改为指向前驱或后继的线索。由于前驱和后继的信息只有在遍历该二叉树时才能得到,所以线索化的过程就是在遍历的过程中修改空指针的过程。
/**
* 线索二叉树
* @author hukai
*
* @param <T>
*/
public class ThreadBinaryTree<T> {
// 根结点
private ThreadedNode<T> root;
// 结点个数
private int size;
// 线索化的时候临时保存前驱
private ThreadedNode<T> tempPre;
// 以默认的构造器创建二叉树
public ThreadBinaryTree() {
this.root = new ThreadedNode<T>();
}
// 以指定根元素创建二叉树
public ThreadBinaryTree(T rootData) {
this.root = new ThreadedNode<T>(rootData);
}
// 以指定数组创建二叉树
public ThreadBinaryTree(T[] datas) {
this.tempPre = null;
this.size = 0;
this.root = createTree(datas, 0);
}
private ThreadedNode<T> createTree(T[] datas,int rootIndex){
// 超出索引范围或者根结点为空,直接返回null
if (rootIndex >= datas.length || datas[rootIndex] == null) return null;
ThreadedNode<T> node = new ThreadedNode<T>(datas[rootIndex]);
size++;
ThreadedNode<T> leftNode = createTree(datas, 2*rootIndex+1);
ThreadedNode<T> rightNode = createTree(datas, 2*rootIndex+2);
node.setLeftNode(leftNode);
node.setRightNode(rightNode);
return node;
}
/**
* 中序线索化
*/
public void inThreading(ThreadedNode<T> root){
if (root == null) return;
// 线索化左孩子
inThreading(root.getLeftNode());
// 左孩子为空,将左孩子设置为线索
if (root.getLeftNode() == null) {
root.setLeftThreadFlag(true);
root.setLeftNode(tempPre);
}
// 上一个节点右孩子为空,将右孩子设置为线索
if (tempPre != null && tempPre.getRightNode() == null) {
tempPre.setRightThreadFlag(true);
tempPre.setRightNode(root);
}
tempPre = root;
// 线索化右孩子
inThreading(root.getRightNode());
}
/**
* 返回根结点
* @return
*/
public ThreadedNode<T> root(){
return root;
}
/**
* 返回元素个数
* @return
*/
public int size(){
return size;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
注意上面的代码中,在使用数组初始化二叉树的时候,采用了递归的方式。而在将二叉树中序线索化时同样使用了递归的方式,代码结构也几乎完全与二叉树中序遍历的递归代码一样。所以同理也可以对比二叉树的前序遍历和后序遍历推导出前序线索化和后序线索化的方法。
# 3. 遍历线索二叉树
有了线索二叉树后,我们对它进行遍历时发现,其实就等于是操作一个双向链表结构。
/**
* 中序遍历线索二叉树
* @param root
*/
public void inThreadList(ThreadedNode<T> root) {
if (root == null) return;
// 查找中序遍历的起始节点
while (root != null && !root.isLeftThreadFlag()) {
root = root.getLeftNode();
}
do {
System.out.print(root.getData() + " ");
// 如果右孩子是线索
if (root.isRightThreadFlag()) {
root = root.getRightNode();
}else{
// 有右孩子
root = root.getRightNode();
while(root != null && !root.isLeftThreadFlag()){
root = root.getLeftNode();
}
}
} while (root != null);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
从这段代码也可以看出,它等于是一个链表的扫描,所以时间复杂度为0(n)。
由于它充分利用了空指针域的空间(这等于节省了空间),又保证了创建时的一次遍历就可以终生受用前驱后继的信息(这意味着节省了时间)。所以在实际问题中,如果所用的二叉树需经常遍历或査找结点时需要某种遍历序列中的前驱和后继,那么采用线索二叉链表的存储结构就是非常不错的选择。